
توصل العالم اللغوي الأميركي جورج زيف في العام 1935 إلى اكتشاف هام؛ حيث كان زيف يدرس العلاقة بين الكلمات الشائعة والأقل شيوعاً، فكان يعدُّ تكرار الكلمات في اللغة الاعتيادية، ثم يرتبها وفقاً لتكرارها.
وكشفت النتائج عن انتظام واضح ومثير للاهتمام، فقد لاحظ "زيف" وجود تناسب عكسي بين موقع الكلمة في الترتيب وتكرارها؛ أي أن الكلمة الثانية في الترتيب تظهر في اللغة بعدد مرات يساوي نصف عدد مرات ظهور الكلمة الأولى، وكذلك فإن الكلمة الثالثة في الترتيب تظهر بمقدار الثلث مقارنة مع الكلمة الأولى، وهكذا.
وتحتل كلمة (the) في اللغة الإنكليزية المرتبة الأولى في التكرار، وتشكل حوالي 7% من مجمل الكلمات المستخدمة، وتليها كلمة (and) التي تتكرر بنسبة 3.5% (لاحظ التناسب المذكور سابقاً)، وهكذا. كما تبين أن حوالي 135 كلمة تشكل نصف الاستخدام الكلي للكلمات، وبالتالي توجد بضعة كلمات تظهر كثيراً، في حين أن أغلب الكلمات الأخرى تكاد لا تستخدم البتة.
ولكن ما السبب؟ من الأسباب المحتملة والمثيرة للاهتمام أن الدماغ يعالج الكلمات الشائعة بشكل مختلف، ودراسة توزيع زيف يمكنها أن تكشف معلومات هامة حول هذه العملية الدماغية.
ولكن هناك مشكلة؛ حيث إن اللغويين لا يُجمعون على أن التوزع الإحصائي لتكرار الكلمات ناتج عن العمليات الإدراكية، ويقول البعض إنه ناتج عن أخطاء إحصائية مترافقة في الكلمات ذات التكرار المنخفض، مما يؤدي إلى ظهور توزعات مشابهة.
ولا شك في أن ما نحتاج إليه هو إجراء دراسة أكبر تشمل نطاقاً واسعاً من اللغات، ويمكن لدراسة بهذا المستوى أن تكون أكثر قوة من الناحية الإحصائية، وقادرة على حسم هذه الاحتمالات.
وقد حصلنا اليوم على دراسة من هذا الشكل، وذلك بفضل عمل شويوان يو وزملائه في جامعة الاتصال الصينية في بكين؛ حيث اكتشف هؤلاء الباحثون وجودَ قانون زيف في 50 لغة تنتمي إلى نطاق واسع من التصنيفات اللغوية، بما فيها الهندو-أوروبية، والأورالية، والألطية، والقوقازية، والصينية-التيبيتية، والدرافيدية، والأفريقية-الآسيوية... وغيرها.
يقول الباحثون إن تكرارات الكلمات في هذه اللغات يشترك في بنية واحدة تختلف عما يمكن أن ينتج عن الأخطاء الإحصائية، كما يقولون إن هذه البنية تقترح أن الدماغ يعالج الكلمات الشائعة بشكل مختلف عن الكلمات قليلة الاستخدام؛ وهي فكرة ذات نتائج هامة بالنسبة لمعالجة اللغة الطبيعية والتوليد الآلي للنصوص.
واتبع الباحثون طريقة مباشرة في العمل، فقد بدؤوا بمجموعتين ضخمتين من النصوص، وهما المجموعة اللغوية البريطانية الوطنية، ومجموعة لايبزيج اللغوية، وتتضمن المجموعتان عينات من 50 لغة مختلفة، وتحتوي كل عينة على الأقل على 30,000 جملة، وما يصل إلى 43 مليون كلمة.
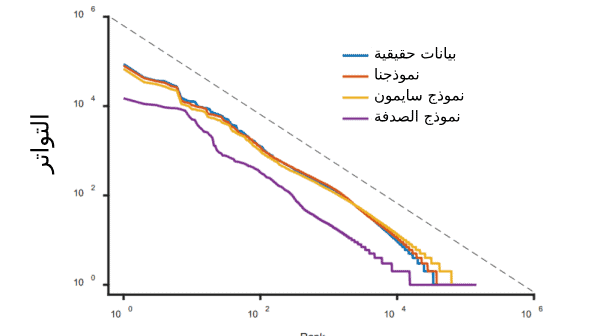
ووجد الباحثون أن تكرار الكلمات في جميع اللغات يخضع لشكلٍ معدَّلٍ من قانون زيف، حيث يمكن تقسيم التوزيع إلى ثلاثة أقسام؛ يقول يو: "تُبيِّن النتائج الإحصائية أن قانون زيف يأخذ -في 50 لغة- نفس الشكل ذي الأقسام الثلاثة، ويتميز كل قسم بصفات لغوية خاصة".
ويعتبر هذا الشكل مثيراً للاهتمام، وقد حاول يو وزملاؤه محاكاته باستخدام عدد من النماذج لتشكيل الكلمات، ومن هذه النماذج: نموذج القرد الضارب على الآلة الكاتبة (نموذج الصدفة)، وهو يولِّد أحرفاً عشوائية تشكل كلمات عند ظهور محرف المسافة. وقد أدت هذه العملية إلى توليد توزُّع تتغير فيه القيم بشكل مضاعف مشابه لتوزُّع زيف، غير أنه لم يولِّد الشكل ثلاثي الأقسام الذي اكتشفه يو وزملاؤه، كما أن من غير الممكن توليد هذا الشكل بالأخطاء الناتجة عن الكلمات ذات التكرار المنخفض، ولكن يو وزملاءه تمكنوا من إعادة إنتاج الشكل الثلاثي باستخدام نموذج يحاكي طريقة عمل الدماغ، ويسمى بنظرية العملية المزدوجة، وتقول هذه الفكرة إن الدماغ يعمل بطريقتين مختلفتين.
الطريقة الأولى هي التفكير البديهي السريع الذي يتطلب قدراً ضئيلاً من المعالجة المنطقية، وقد لا يتطلبه أصلاً، ويُعتقد بأن هذا النوع من التفكير قد تطوَّر حتى سمح للبشر بالتصرف بسرعة في الأوضاع الخطيرة، وهو يعطي غالباً حلولاً جيدة للمشاكل الصعبة مثل التعرف على الأنماط، ولكن يمكن خداعه بسهولة في الأوضاع غير البديهية.
غير أن البشر قادرون على تفكير أكثر منطقية بكثير، وهو ما يحدث في الطريقة الأخرى الأكثر بطئاً ودقة، والتي تعمل بشكل متعمد ومقصود، وهو التفكير الذي يسمح لنا بحل المشاكل المعقدة، مثل الألغاز الرياضية وغيرها.
وتقترح نظرية العملية المزدوجة أن الكلمات الشائعة مثل the وand وif وغيرها تتم معالجتها بالتفكير السريع البديهي، ولهذا فهي تستخدم بكثرة، وتعتبر هذه الكلمات بمنزلة العمود الفقري للجمل، أما الكلمات الأقل شيوعاً مثل hypothesis و Zipf’s law فتتطلب تفكيراً أكثر دقة، ولهذا فهي لا تتكرر كثيراً.
وبالفعل عندما قام يو وزملاؤه بمحاكاة هذه العملية المزدوجة، تمكنوا من الحصول على نفس الشكل ثلاثي الأقسام لتوزُّع تكرار الكلمات الذي حصلوا عليه بالقياس في 50 لغة.
ويعبر القسم الأول عن توزع الكلمات الشائعة، والأخير عن توزع الكلمات قليلة الاستخدام، أما القسم الأوسط فهو ناتج -ببساطة- عن تراكب القسمين السابقين. يقول الباحثون: "تُبيِّن النتائج أن قانون زيف في اللغات ناتج عن الآليات الإدراكية، مثل العملية المزدوجة، التي تحكم السلوكيات اللفظية عند البشر".
إن هذا العمل مثير للاهتمام؛ حيث إن فكرة معالجة الدماغ البشري للمعلومات بطريقتين مختلفتين قد اكتسبت زخماً جيداً في السنوات الماضية، خصوصاً وأن كتاب "Thinking, Fast and Slow" -لعالم النفس الفائز بجائزة نوبل دانييل كاينمان- قد درس هذه الفكرة بالتفصيل.
ومن المسائل الشهيرة المستخدمة لتشغيل التفكير السريع والبطيء هذه المسألة: "لدينا كرة ومضرب، ويبلغ سعرهما معاً 1.1 دولار، ويزيد سعر المضرب على سعر الكرة بمقدار 1 دولار. كم سعر الكرة؟"
الجواب بالطبع هو 5 سنتات (0.05 دولار)، غير أن الجميع تقريباً يميلون إلى الاعتقاد بأن الجواب هو 10 سنتات، فهو يبدو لنا صحيحاً، وذلك لأنه من الرتبة الصحيحة، كما أنه هو الذي تقترحه صياغة المسألة بشكل مباشر. وهذا الجواب ينتج عن الجزء السريع البديهي من الدماغ، ولكنه خاطئ، أما الجواب الصحيح فيحتاج حسابه إلى التفكير الأبطأ والأكثر دقة.
يقول يو وزملاؤه إن هاتين العمليتين تستخدمان في توليد الجمل، حيث يقوم الجزء السريع من الدماغ بتوليد البنية الأساسية من الجملة (أي الكلمات شائعة الاستخدام)، فيما يتطلب استخدام الكلمات الأخرى الجزء الأبطأ والأكثر دقة، وهذه العملية المزدوجة هي التي تؤدي إلى الأقسام الثلاثة في قانون زيف.
وقد يؤدي هذا العمل إلى نتائج هامة بالنسبة لعلماء الحاسوب الذين يعملون على معالجة اللغة الطبيعية، وقد تم بالفعل تحقيق إنجازات كبيرة في هذا الحقل مؤخراً، وتُعزى هذه الإنجازات إلى خوارزميات التعلم الآلي وقواعد البيانات النصية الضخمة التي ولَّدتها شركات مثل جوجل.
غير أن توليد اللغة الطبيعية ما زال عملية صعبة، وليس من الممكن أن تتحاور مع سيري أو كورتانا أو جوجل أسيستانت لفترة طويلة دون الاصطدام بحدود الإمكانيات الحوارية لهذه المساعدات الرقمية، ولهذا فإن فهم كيفية توليد الجمل البشرية بشكل أفضل سيساعدنا على تحقيق الكثير في هذا المجال، ولا شك في أن زيف سيُعجب بهذا العمل.