
تعد "الأمثلة المُربكة" نوعاً من أنواع التغييرات الطفيفة، التي عندما ندرجها ضمن نموذج للتعلم العميق تجعله يسيء التصرف. خلال شهر مارس، كنا قد نقلنا حديث داون سونغ، الأستاذة بجامعة كاليفورنيا في بيركلي، ضمن فعاليات المؤتمر الرقمي السنوي "إيميتك"، حيث تكلمت عن الطريقة التي استخدمت بها الملصقات لخداع سيارة ذاتية القيادة بشكل يجعل ذكاءها الاصطناعي يظن أن علامة مرورية تفيد التوقف هي علامة مرورية أخرى تعني تحديد السرعات بـ45 ميلاً في الساعة، وكيف أن الأستاذة داون استخدمت رسائل معينة جعلت نموذج ذكاء اصطناعي قائم على الدردشة النصية يبوح بمعلومات شخصية حساسة مثل رقم بطاقات الائتمان. وبحلول شهر أبريل، كتبنا مقالاً عن أن القراصنة ذوي القبعة البيضاء (الذين يوجهون جهودهم لأغراض مفيدة، بخلاف القراصنة ذوي القبعة السوداء) قاموا باستخدام الملصقات لإرباك نظام تسلا للقيادة الذاتية (Tesla Autopilot) بشكل جعله يقود السيارة إلى الاتجاه الخطأ.
وفي السنوات الأخيرة، وفي ظل انتشار نُظُم التعلم العميق إلى حد بعيد في حياتنا العامة والشخصية، بيَّن العلماء والباحثون أكثر من مرة أن "الأمثلة المُربكة" بإمكانها التأثير على كافة أنواع الذكاء الاصطناعي، بدءاً بمُصنِّفات الصور البسيطة إلى نُظُم تشخيص السرطان، الأمر الذي سيؤدي إلى عواقب تتراوح من العادية (التي لا تُحدث ضرراً) إلى الوخيمة (التي تهدد حياة البشر).
لكن "الأمثلة المُربكة" -على الرغم من مخاطرها- ما زالت لم تعطَ حقها من الدراسة والتفحص، وبالتالي فليس لدينا فهم كامل عنها حتى الآن. ولهذا يشعر العلماء والباحثون بالقلق حيال كيفية حل المشكلة، بل إن بعضهم يشكُّ في إمكانية حلها أساساً.
بيد أن هناك بصيصَ أمل لاح بعد صدور ورقة علمية حديثة من جامعة إم آي تي، تشير إلى درب محتمل يمكن أن يُفضي بنا إلى تجاوز هذا التحديّ. وتتحدث الدراسة عن إمكانية تتيح لنا إنشاء نماذج تعلم عميق مُحكمة جداً بشكل يجعل من الصعب للغاية التلاعب بها لأغراضٍ سيئة. ولإدراك أهمية نتائج هذه الدراسة، دعنا أولاً نستذكر بسرعة أساسيات "الأمثلة المُربكة ."
تكمن نقطة قوة نماذج "التعلم العميق"، كما ذكرنا ذلك من قبل عدة مرات، في قدرتها الفائقة على رصد الأنماط ضمن حزم البيانات. ولهذا عندما نُغذّي شبكة عصبونية بعشرات الآلاف من صور الحيوانات المرفقة بأسمائها (كل حيوان واسمه)، فستتعلم الشبكة العصبونية الأنماط الخاصة بدبّ الباندا، وتلك الخاصة بالقرد. ومن ثم تستخدم الشبكة العصبونية تلك الأنماط التي رصدتها للتعرف على تلك الحيوانات حتى لو عرضنا عليها صوراً جديدة لها لم ترها من قبل.
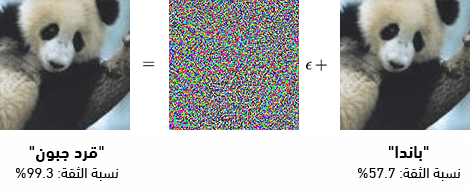
هذه هي نقطة قوة نماذج التعلم العميق، لكن لا تنسَ أن لديها نقطة ضعف أيضاً؛ إذ إن نُظم التعرف على الصور يسهل خداعها من خلال التلاعب بأنماط البكسل بشكل يجعل النظام يرى شيئاً آخر تماماً، وذلك لأنها تعتمد فقط على الأنماط البكسلية بدل اعتمادها على مستوى أعمق من "الفهم التصوري" لِما تراه. وهنا سنتناول مثالاً تقليدياً على ذلك: يكفي أن تضيف قليلاً من التشويش لصورة تمثل "باندا"، وسيقوم نظام التعرّف على الصور بتصنيفها على أنه "جِبون gibbon" (نوع من القرود) بنسبة ثقة تقارب 100%! وهذا "التشويش" يسميه الباحثون في المجال: "هجوماً مُربكاً adversarial attack".
مصدر الصورة: IAN GOODFELLOW ET AL/OPENAI
وقد لاحظ العلماء والباحثون هذه الظاهرة منذ عدة سنوات، لا سيما ضمن اختباراتهم لنُظُم الرؤية الحاسوبية، لكنهم لم يكتشفوا بعد طريقة ناجعة 100% لسدِّ هذه الثغرة. حتى إن إحدى الدراسات الحديثة التي عُرضت الأسبوع الماضي في أحد أكبر مؤتمرات بحوث الذكاء الاصطناعي العالمية: ICLR (المؤتمر العالمي لتمثيلات التعلم)، ذهبت إلى أن التصدي التام لـ"الهجومات المُربكة" قد يكون مستحيلاً؛ إذ يبدو أنه مهما كان عدد صور حيوانات الباندا التي تغذَّى بها نظام مُصنِّف الصور، سيظل الباب مفتوحاً على الدوام لتصميم نوع من أنواع التلاعب التي تجعل نظام التعرّف يخطئ أو يسيء التقدير.
لكن الدراسة الجديدة التي صدرت عن جامعة إم آي تي، تُبيّن أن فهمنا لـ"الهجمات المُربكة" مجانب للصواب؛ إذ تشير الدراسة إلى أنه ينبغي علينا أن نعيد التفكير من البداية بالطريقة التي ندرّب بها النظام أساساً، بدلاً من التفكير في أساليب لتغذية نظام الذكاء الاصطناعي بكمّ أكبر وأفضل جودة من البيانات التي سيتدرب عليها.
وقد أثبتت الدراسة صحة هذا النهج، وذلك من خلال الكشف عن خاصيّة لافتة للنظر للأمثلة المُربكة، من شأنها مساعدتنا على أن نفهم بشكل أعمق لماذا نجد الأمثلة المُربكة فعّالة جداً في التلاعب بنُظم الذكاء الاصطناعي؛ وذلك أن التشويش أو الملصقات -العشوائية ظاهرياً- التي تجعل الذكاء الاصطناعي يخطئ في تصنيف الصور أو الأغراض، ليست اعتباطية في الواقع، بل تستند في حقيقة الأمر على أنماط صغيرة جداً ودقيقة للغاية تَعَلَّمَ النظامُ من قبل أن يربطها بشكل وثيق بأغراض وتسميات محددة.
بعبارة أخرى: الآلة لا تخطئ حقاً عندما ترى إحدى الصور "قرد جِبون" ونراها "باندا"؛ حيث إن الآلة تدرك بالفعل نمطاً من البكسلات، لا ندركه نحن البشر، فهي ترصد الآلة أثناء تدريبها وجود ذلك النمط غالباً في صور "قرد الجِبون" أكثر من وجوده في صور "الباندا".
وقد قام الباحثون في الدراسة بتوضيح هذه النتيجة بإجراء تجربة؛ حيث أنشأوا مجموعة من البيانات تضم صوراً لكلاب غُيّرت جميعها بشكل طفيف يجعل نُظُم التصنيف العادية تصنفها على أنها قطط. وبعد ذلك صنفوا تلك الصور بشكل خاطئ عمداً على أنها "قطط" واستخدموها لتدريب شبكة عصبونية جديدة من الصفر. وبعد التدريب، عرضوا على تلك الشبكة العصبونية صوراً لقطط حقيقية هذه المرة، والنتيجة كانت قيام الشبكة العصبونية بتصنيفها بشكل صحيح على أنها قطط.
أما ما استنتجه الباحثون من هذه التجربة فهو أن هناك في كل مجموعة من البيانات نوعان من الارتباطات: أنماط ترتبط بالفعل بالمعنى الذي تحتويه البيانات، مثل الشوارب في صور القطط وألوان الفراء في صور الباندا، وأنماط صَدَفَ وأن وُجدت في البيانات التي دُرّب عليها النظام لكن لا ينبغي أن يعول عليها في سياقات أخرى. وهذه الأخيرةـ -وهي الارتباطات "المُضللة" كما سنسميها من الآن فصاعداً- هي الارتباطات التي تستغلها "الهجمات المُربكة" للتلاعب بالذكاء الاصطناعي.
وإذا أخذنا المثال المصوّر أعلاه، فسنجد أن الهجوم المربك استغل نمط البكسل المرتبط خطأً مع "قرد الجِبون"، وذلك من خلال تضمين تلك البكسلات الخاصة بالقرد الجِبون (بشكل غير محسوس للبشر) داخل صورة الباندا، فلا جَرَم إذن أن يرصد نظام التعرف على الصور -الذي دُرّب على التعرّف على النمط المضلل- ذلك النمط ويفترض أن الصورة الماثلة أمامه صورة "قرد جِبون".
وهذا ما يشير إلى أنه إن أردنا القضاء على مخاطر "الهجمات المُربكة" لنُظُم الذكاء الاصطناعي، فلا بد لنا من أن نغيّر الطريقة التي ندرّب بها هذه النُظُم. وفي الوقت الراهن، يتيح الباحثون والمطورون للشبكات العصبونية أن تختار ما تشاء من الارتباطات التي تريد استخدامها لتصنيف الأغراض أو الحيوانات التي تحتويها الصور. لكن هذه الحرية تؤدي إلى فقدان سيطرتنا على الارتباطات التي تجدها الشبكات العصبونية، وتجعلنا غير متأكدين من مدى موثوقية تلك الارتباطات: هل هي حقيقية أم مُضللة؟
فتصوّر الآن لو أننا بدلاً من أن نفسح المجال للشبكات العصبونية لتختار ما تشاء من ارتباطات، قمنا بتدريبها على تذكر الأنماط الصحيحة والحقيقية فقط -أي تلك الأنماط التي ترتبط حقاً بما تضمه الصور (ومن ثم البكسلات) من معاني، عندئذ سيكون بإمكاننا -ولو على مستوى نظري- تطوير نُظُم تعلم عميق لا يمكن تضليلها لأغراض إيقاع الضرر والإيذاء.
وفي هذا الجانب، عندما اختبر الباحثون الذين ألفوا الدراسة هذه الفكرة باستخدام الارتباطات الحقيقة فقط لتدريب نظامهم من الذكاء الاصطناعي، تمكن النظام بالفعل من تخفيف حدّة خطأه وانسياقه للتضليل والتلاعب، حيث لم تستطع الصور المخادعة تضليله إلا بنسبة 50% من إجمالي مرات التجريب، في حين أن النُظُم المدرّبة على الارتباطات الصحيحة والخاطئة معاً ضُللت بنسبة 95%.
وبعبارة أخرى، يبدو أن "الأمثلة المُربكة" ليست تحدياً غير قابل للصدّ أو التجاوز. لكننا بطبيعة الحال، ما زلنا في حاجة إلى المزيد من البحوث والدراسات للقضاء على المشكلة نهائياً.