
لقد كان من الواضح أن أوبن إيه آي تنوي فعل شيء ما. ففي أواخر عام 2021، كان فريق صغير من الباحثين يستكشف إحدى الأفكار في مكتب الشركة بمدينة سان فرانسيسكو. فقد قاموا ببناء نسخة جديدة من نموذج أوبن إيه آي لتحويل النص إلى صور، دال-إي، وهو نظام ذكاء اصطناعي يحوّل التوصيفات النصية القصيرة إلى صور، مثل ثعلب مرسوم من قبل فان غوخ، أو كلب كورغي مصنوع من البيتزا. وكانوا يحاولون أن يحددوا ما يمكن فعله بهذا النظام.
يقول أحد مؤسسي أوبن إيه آي ورئيسها التنفيذي، سام ألتمان، لإم آي تي تكنولوجي ريفيو: "في جميع الحالات تقريباً، نقوم أولاً ببناء شيء ما، ومن ثم نقوم باستخدامه لفترة من الوقت. ونحاول تحديد شكله النهائي، والهدف الذي سيتم استخدامه من أجله".
ولكن، ليس هذه المرة. فعندما كان الجميع يجرون التجارب على النموذج، أدركوا أنه شيء خاص. يقول ألتمان: "لقد كان من الواضح تماماً أننا توصلنا إلى شيء خاص للغاية، وأنه المنتج الذي كنا نسعى إلى بنائه. لم يكن هناك أي جدال حول هذه المسألة، بل لم نقم حتى بعقد اجتماع لمناقشتها".
اقرأ أيضاً: شرح تكنولوجيا أوبن إيه آي لاستخدام الذكاء الاصطناعي في كتابة القصص الخيالية وتوليد الأخبار المزيفة
ولكن، ما كان لأي شخص –بما في ذلك ألتمان، وفريق دال-إي- أن يتوقع مدى الصدمة التي سيحدثها هذا المنتج. يقول ألتمان: "إنها أولى تكنولوجيات الذكاء الاصطناعي التي حققت شعبية واسعة بين الناس العاديين".
عام من النماذج التوليدية
تم إطلاق دال-إي 2 في أبريل/ نيسان من عام 2022. وفي مايو، أعلنت جوجل (Google) أنها ستطلق نموذجين خاصين بها لتحويل النص إلى صور، إيماجين (Imagen) وبارتي (Parti)، ولكنها لم تفعل. وبعد ذلك، ظهر نموذج تحويل النص إلى صور للفنانين، ميدجورني (Midjourney). أما في شهر أغسطس/ آب، ظهر ستيبل ديفيوجن (Stable Diffusion)، وهو نموذج مفتوح المصدر أطلقته الشركة الناشئة البريطانية ستابيليتي أيه آي (Stability AI) مجاناً للعامة.
وتدفقت الحشود. فقد قام مليون مستخدم بالتسجيل لدى أوبن أيه آي في شهرين ونصف وحسب. كما بدأ أكثر من مليون شخص باستخدام ستيبل ديفيوجن عبر منصة الاستخدام الخاصة به دريم ستوديو (Dream Studio) المدفوعة، وخلال أقل من نصف تلك الفترة، واستخدم عدد إضافي من المستخدمين ستيبل ديفيوجن أيضاً عبر تطبيقات أخرى، أو قاموا بتنصيب النسخة المجانية على حواسيبهم. ويقول عماد موستاك، وهو مؤسس ستابيليتي إيه آي، إنه يهدف إلى اجتذاب مليون مستخدم.
وفي أكتوبر، بدأت الجولة الثانية، وهي مجموعة من نماذج تحويل النص إلى مقاطع فيديو من جوجل (Google)، وميتا (Meta)، وغيرها. فبدلاً من مجرد توليد صور جامدة، تستطيع هذه النماذج تشكيل مقاطع فيديو وصور متحركة قصيرة وصور ثلاثية الأبعاد.
لقد كانت وتيرة التطور مذهلة. فخلال بضعة أشهر وحسب، تمكنت هذه التكنولوجيا من شغل العديد من العناوين الصحافية وأغلفة المجلات، وملء وسائل التواصل الاجتماعي بالميمات، ودفعت ماكينة الضجيج الإعلامي للعمل بوضعية السرعة الفائقة، كما أثارت موجة شديدة من الانتقادات وردود الفعل السلبية.
يقول باحث الذكاء الاصطناعي في كلية لندن الملكية، والذي يدرس الابتكار الحاسوبي، مايك كوك: "إن الصدمة والإعجاب الناجمين عن هذه التكنولوجيا أمر رائع، ومثير للحماس، وهو ما يجب أن تتصف به التكنولوجيات الجديدة. ولكن التقلبات أصبحت سريعة للغاية إلى درجة أن التوقعات الأولية أصبحت تتغير حتى قبل الاعتياد على الفكرة، وأعتقد أن المجتمع سيحتاج إلى بعض الوقت لاستيعاب ما يحدث بالشكل الصحيح".
اقرأ أيضاً: نظام ذكاء اصطناعي يفيض خيالاً من أوبن إيه آي بدأ يتعلّم توليد الصور
الفنانون: الشريحة المهَددة
لقد وجد الفنانون أنفسهم في خضم أحد أكبر الاضطرابات لهذا الجيل. فقد يتعرض بعضهم لفقدان مصدر دخله، على حين قد يجد البعض الآخر فرصاً جديدة للعمل. بل إن البعض قرر اللجوء إلى المحاكم لخوض معارك قانونية حول ما يعتبرونه إساءة استخدام للصور في تدريب النماذج التي قد تحل محلهم في نهاية المطاف.
يقول الفنان الرقمي الذي يعمل في كاليفورنيا دون آلين ستيفنسون الثالث، والذي عمل مع العديد من استوديوهات المؤثرات المرئية، مثل دريم ووركس، إن ما حدث كان مفاجأة كبيرة للمبتكرين. ويقول: "بالنسبة للأشخاص المدربين تقنياً من أمثالي، يمثل ما يحدث وضعاً مخيفاً للغاية. فهو يوحي بفقدان مصدر دخلي بالكامل. لقد وجدت نفسي أواجه أزمة وجودية خلال الشهر الأول من استخدام دال-إي".

ولكن، وفيما يحاول البعض استعادة توازنهم بعد الصدمة، بدأ الكثيرون غيرهم –بما فيهم ستيفنسون- باكتشاف وسائل لاستخدام هذه الأدوات، وتوقع ما يمكن أن يحدث لاحقاً.
أما الحقيقة المثيرة للحماس، فهي أننا لا نعرف ما يمكن أن يحدث حقاً. ولكن الصدمة ستؤثر أولاً، ولبعض الوقت، على الصناعات الابتكارية، بدءاً من وسائط الترفيه وصولاً إلى الموضة والعمارة والتسويق وغيرها، فهذه التكنولوجيا التي تكاد تشبه قوة خارقة ابتكارية ستصبح متاحة للجميع. أما على المدى الطويل، فقد يصبح بالإمكان استخدامها لتوليد تصاميم لأي شيء تقريباً، بدءاً من أنواع جديدة من العقاقير وصولاً إلى الملابس والأبنية. لقد بدأت الثورة التوليدية.
ثورة سحرية
بالنسبة للفنان الرقمي المختص بألعاب الفيديو والبرامج التلفزيونية، تشاد نيلسون، فإن نماذج تحويل النص إلى صور تمثّل إنجازاً لا يحدث سوى مرة واحدة في العمر. ويقول: "تنقلك هذه التكنولوجيا من الفكرة الأولية الموجودة في ذهنك إلى إنجاز الرسم الأولي خلال ثوانٍ معدودة. إن السرعة الممكنة في الابتكار والتجريب إنجاز ثوري يتجاوز أي شيء شهدتُه على مدى 30 سنة".
وخلال أسابيع من إطلاق هذه الأدوات لأول مرة، كان الناس يستخدمونها لإنجاز نماذج أولية وطرح أفكار لكل شيء، بدءاً من الرسومات التوضيحية في المجلات، ومخططات التسويق، وصولاً إلى بيئات ألعاب الفيديو والتصاميم الأولية للأفلام. وقد قام البعض بتوليد أعمال فنية مستوحاة من إعجابهم بأعمال فنية أو شخصيات شهيرة، بل وقاموا حتى بتوليد قصص مصورة كاملة، وشاركوها على الإنترنت بالآلاف. حتى إن ألتمان استخدام دال-إي في توليد تصاميم لأحذية رياضية قام أحدهم لاحقاً بصنعها له بعد نشر الصور في تغريدة على الإنترنت.
كما أن عالمة الحاسوب في جامعة كوين ماري في لندن، إيمي سميث -وهي فنانة وشوم أيضاً- كانت تستخدم دال-إي في تصميم الوشوم. وتقول: "يمكنك ببساطة الجلوس مع أحد العملاء ووضع التصاميم سوية. إننا نعيش ثورة في توليد الوسائط".
ويعتقد الفنان الرقمي وفنان الفيديو الذي يعمل في كاليفورنيا، بول تريلو، أن هذه التكنولوجيا ستجعل طرح أفكار المؤثرات المرئية أكثر سهولة وسرعة. ويقول: "يعتقد الكثيرون أن هذه التكنولوجيا تمثل نهاية فناني المؤثرات المرئية، ومصممي الموضة. ولكنني لا أعتقد أنها تمثل نهاية أي شيء. بل أعتقد أنها وسيلة تسمح لنا أن نعمل بسرعة، بدلاً من العمل طوال الليل وفي عطلة نهاية الأسبوع".
مواقف متباينة للمواقع والخدمات التي تقدم المؤثرات المرئية
أما شركات خدمات تقديم وتخزين ملفات الصور والصوت والفيديو العامة فقد اتخذت مواقف مختلفة. فقد حظرت غيتي (Getty) الصور المولدة باستخدام الذكاء الاصطناعي. أما شاترستوك (Shutterstock) فقد وقّعت اتفاقاً مع أوبن أيه آي لدمج دال-إي في موقعها الإلكتروني، وتقول إنها ستُطلق صندوقاً لدفع التعويضات للفنانين الذين تم استخدام أعمالهم لتدريب النماذج.
ويقول ستيفنسون إنه جرب دال-إي في جميع خطوات العملية التي يستخدمها أحد استوديوهات الرسوم المتحرك في إنتاج الأفلام، بما فيها تصميم الشخصيات والبيئات. وبفضل دال-إي، تمكن من إنجاز عمل عدة أقسام خلال بضع دقائق. ويقول: "إنه إنجاز رائع ومريح بالنسبة لجميع الأشخاص الذين كانوا عاجزين عن الابتكار بسبب التكاليف أو الصعوبات التقنية. ولكنه أمر مرعب أيضاً لمن ليسوا منفتحين على التغيير".
اقرأ أيضاً: ما الذي قد يحدث إذا تحول الذكاء الاصطناعي من أداة إلى كائن حي؟
ويعتقد نيلسون أننا سنشهد المزيد مستقبلاً. ويعتقد أن هذه التكنولوجيا في نهاية المطاف، ستحوز قبول الشركات العملاقة في مجال الوسائط، وحتى المهندسين المعماريين وشركات التصميم. ولكنه يضيف قائلاً إن هذه التكنولوجيا لم تصل إلى مرحلة النضج بعد.
ويقول: "حالياً، يمكن تشبيهها بصندوق سحري صغير، أو ساحر صغير". إنه لأمر رائع إذا كنت ترغب فقط في مواصلة توليد الصور، ولكنه ليس كافياً إذا كنت تبحث عن شريك إبداعي. ويضيف: "فإذا أردتُ ابتكار القصص وبناء العوالم، يجب أن يكون هذا الشريك أكثر إدراكاً لما أرغبُ في ابتكاره".
وهنا تكمن المشكلة، فهذه النماذج ما زالت عاجزة عن استيعاب ما تقوم به.
داخل الصندوق الأسود
حتى ندرك السبب، علينا أن نلقي نظرة على طريقة عمل هذه البرامج. فمن الخارج، تبدو هذه البرامج كصندوق أسود. حيث يقوم المستخدم بطباعة توصيف صغير، أو تعليمة نصية، وينتظر بضع ثوانٍ. ويحصل بعدها على مجموعة من الصور التي تعبّر عن التوصيف السابق (بشكل أو بآخر). ومن المحتمل تعديل النص لدفع النموذج إلى إنتاج شيء أقرب إلى تصورك الخاص، أو الحصول على نتيجة عرضية غير متوقعة. وقد أصبح هذا الأسلوب معروفاً باسم هندسة التعليمات النصية.
فالتعليمات التي تهدف إلى إنتاج أكثر الصور جمالاً ودقة قد يصل طولها إلى عدة مئات من الكلمات، كما أن استخدام الكلمات الصحيحة أصبح مهارة مفيدة للغاية. وقد ظهرت أسواق رقمية على الإنترنت للمتاجرة بالتعليمات النصية التي تعطي نتائج مرغوبة.
ويمكن أن تحتوي هذه التعليمات على جمل توجه النموذج نحو استخدام أسلوب معين، فعبارة "trending on ArtStation" (يحقق انتشاراً واسعاً على آرت ستيشن (ArtStation)) توجه الذكاء الاصطناعي نحو استخدام أسلوب خاص (عادةً ما يتضمن الكثير من التفاصيل) من الأساليب المفضّلة في الصور الموجودة على آرت ستيشن، وهو موقع ويب يستعرض عليه الآلاف من الفنانين أعمالهم، كما أن عبارة "Unreal engine" (محرك أنريل [لتطوير الألعاب الحاسوبية]) تدفع الذكاء الاصطناعي نحو استخدام الأسلوب المرئي المألوف في بعض ألعاب الفيديو التي تستخدم هذا المحرك، وغير ذلك. حتى إنه يمكن للمستخدم أن يقوم بإدخال أسماء فنانين محددين حتى يقوم الذكاء الاصطناعي بإنتاج أعمال مستوحاة من أعمالهم، وهو ما أثار حفيظة واستياء العديد من الفنانين.

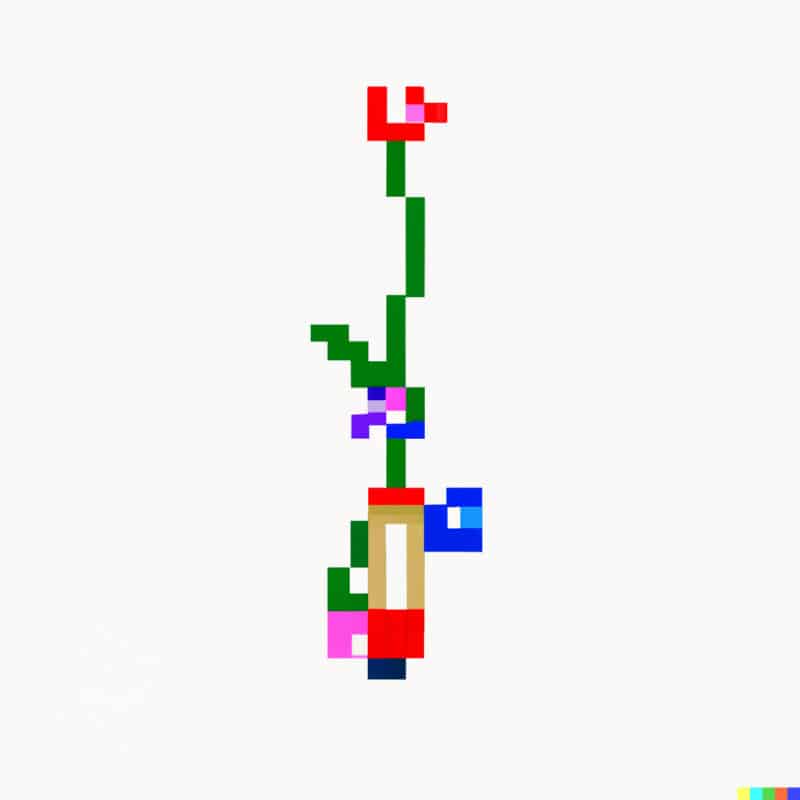
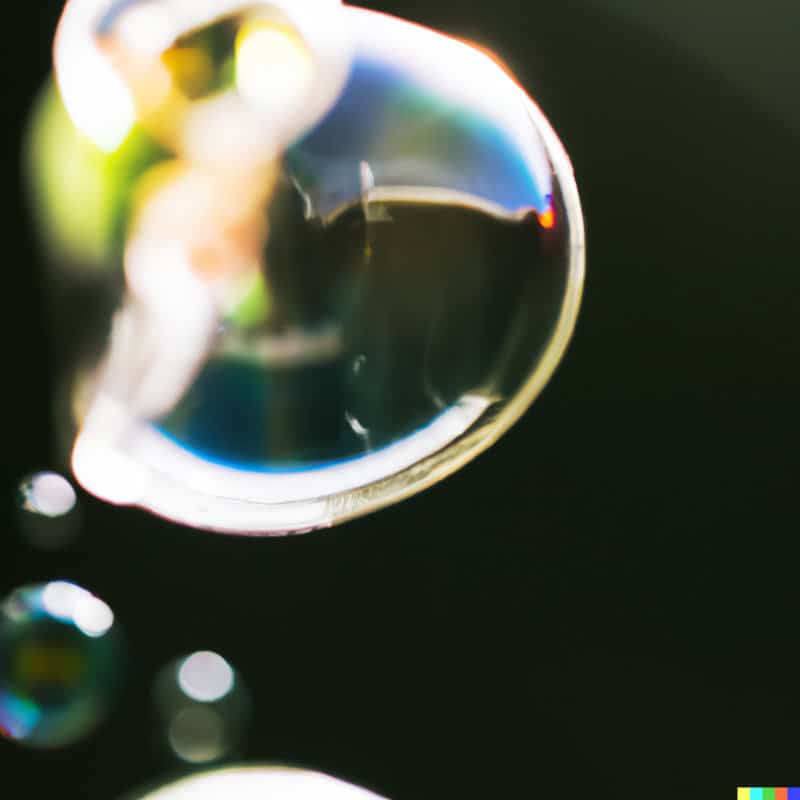
"لقد حاولت تمثيل الذكاء الاصطناعي مجازياً باستخدام التعليمة النصية "the Big Bang" (الانفجار الكبير) وحصلت على هذه الأشكال المجردة الشبيهة بالفقاعات (يمين)" ولم يكن هذا ما أردته بالضبط، ولهذا قررت إضافة المزيد من التفاصيل بعبارة ’explosion in outer space 1980s photograph‘ (انفجار في الفضاء الخارجي في صورة فوتوغرافية من الثمانينيات) (يسار)، وهو ما أعطى نتيجة تميل إلى المبالغة. كما حاولت زراعة بعض النباتات الرقمية باستخدام عبارة ’plant 8-bit pixel art‘ (نبات مرسوم بفن رقمي باستخدام بكسلات 8 بت) (في الوسط)".
تتضمن بنية نماذج تحويل النصوص إلى صور عنصرين أساسيين: شبكة عصبونية واحدة مدربة لإقران صورة مع نص يصف هذه الصورة، وشبكة أخرى مدربة لتوليد الصور بدءاً من الصفر. وتقوم الفكرة الأساسية على استخدام الشبكة العصبونية الثانية لتوليد صورة تقبلها الشبكة العصبونية الأولى كصورة متوافقة مع التعليمة النصية.
اقرأ أيضاً: الذكاء الاصطناعي يمكننا من كشف النصوص التي كتبها بنفسه
ويكمن الإنجاز الكبير غير المسبوق الذي تجسده هذه النماذج الجديدة في طريقة توليد الصور. في النسخة الأولى من دال-إي، تم استخدام امتداد للتكنولوجيا التي يعتمد عليها النموذج اللغوي جي بي تي 3 (GPT-3) من أوبن أيه آي، لإنتاج الصور عن طريق التنبؤ بالبكسل التالي في الصور، وكأنها كلمات ترد ضمن الجمل. وقد نجحت هذه الطريقة، ولكن ليس بدرجة مرضية. يقول ألتمان: "لم تكن بالتجربة السحرية. ومن المذهل أنها نجحت في المقام الأول".
نموذج الانتشار
وبدلاً من هذا، يعتمد دال-إي 2 على ما يسمى بنموذج الانتشار. وتُعرف نماذج الانتشار بأنها شبكات عصبونية مدربة على تنظيف الصور بإزالة ضجيج البكسلات الناجم عن عملية التدريب. وتتضمن العملية تعديل بضعة بكسلات في الصورة كل مرة، وتكرار العملية مرات عديدة، حتى تزول الصورة الأصلية ولا تبقى منها سوى بكسلات عشوائية. يقول بيورن أومر، الذي عمل على الذكاء الاصطناعي التوليدي في جامعة ميونيخ في ألمانيا، والذي ساعد في بناء نموذج انتشار يعتمد عليه برنامج ستيبل ديفيوجن حالياً: "عند تكرار العملية آلاف المرات، نحصل في نهاية المطاف على ما يشبه صورة تلفاز تم نزع كابل الهوائي منه، في منظر يشبه تساقط الثلج إلى حد كبير".
يتم تدريب الشبكة العصبونية بعد ذلك لعكس هذه العملية وتوقع شكل الصورة بعد انتزاع البكسلات منها. أما الميزة الإيجابية فهي أن نموذج الانتشار سيحاول توليد صورة أكثر وضوحاً من أي مجموعة عشوائية من البكسلات. وعند تلقيمه بصورة جيدة، سيحاول إنتاج صورة أكثر دقة. وعند تكرار هذه العملية مرات عديدة، سينقلك النموذج من شكل شاشة تلفاز مشوشة بالكامل إلى صورة عالية الدقة.
ولكن أنظمة الذكاء الاصطناعي التي تولد الأعمال الفنية لا تعمل كما يراد منها دائماً. وغالباً ما تعطي نتائج قبيحة تبدو كأعمال فنية شائعة مشوهة الشكل في أفضل الأحوال. ووفقاً لتجربتي الخاصة، فإن الطريقة الوحيدة للحصول على نتائج جيدة هي إضافة توصيف في النهاية لتحديد أسلوب مرئي جميل.
إريك كارتر
وتكمن الحيلة في نماذج تحويل النصوص إلى صور في أن هذه العملية خاضعة لسيطرة النموذج اللغوي الذي يحاول مطابقة التعليمة مع الصور التي ينتجها نموذج الانتشار. وهو ما يدفع نموذج الانتشار نحو إنتاج الصور التي يعتبرها النموذج اللغوي موافقة للتوصيف بشكل جيد.
غير أن النماذج لا تستنبط الصلات بين النصوص والصور من تلقاء نفسها. فمعظم نماذج تحويل النصوص إلى صور تخضع للتدريب على قاعدة بيانات كبيرة تحمل اسم لايون (LAION)، والتي تحتوي على المليارات من أزواج التوصيفات النصية والصور، والتي تم جمعها من الإنترنت. وهو ما يعني أن الصور التي تحصل عليها من نموذج لتحويل النصوص إلى صور هي خلاصة للعالم كما يتم تمثيله الإنترنت، والتي تحمل في طياتها تشويهاً ناجماً عن التحيز (والمواد الإباحية أيضاً).
اقرأ أيضاً: ماذا لو نفدت البيانات اللازمة لتدريب نماذج الذكاء الاصطناعي اللغوية؟
يذكر أنه يوجد فرق صغير ولكنه أساسي بين النموذجين الأكثر شيوعاً: دال-إي 2 وستيبل ديفيوجن. فنموذج الانتشار في دال-إي 2 يعمل على صور كاملة الحجم. أما ستيبل ديفيوجن فهو يعتمد على طريقة تحمل اسم الانتشار الكامن (latent diffusion)، والتي ابتكرها أومر وزملاؤه. وتعمل هذه الطريقة باستخدام نسخ مضغوطة من الصور المرمزة ضمن الشبكة العصبونية، وذلك ضمن ما يعرف بالفضاء الكامن (latent space)، حيث يتم الاحتفاظ بالسمات الأساسية للصورة فقط.
وهو ما يعني أن ستيبل ديفيوجن يحتاج في عمله إلى قدرات حاسوبية أقل. وخلافاً لدال-إي 2، والذي يعمل على خوادم أوبن أيه آي عالية القدرة، فإن ستيبل ديفيوجن يستطيع أن يعمل على الحواسيب الشخصية التي تتمتع بمواصفات جيدة. تعود معظم التطورات فائقة السرعة في الابتكار، والتطوير السريع للتطبيقات الجديدة، إلى كون ستيبل ديفيوجن مفتوح المصدر، أي أنه يمكن لأي مبرمج تغييره والبناء عليه وجني المال منه دون أي عوائق، كما أنه لا يحتاج إلى موارد حاسوبية ضخمة، ما يسمح بتشغيله على الحواسيب المنزلية.
تعريف جديد للابتكار
بالنسبة للبعض، تمثّل هذه النماذج خطوة إلى الأمام نحو تحقيق الذكاء العام الاصطناعي (AGI)، وهو مصطلح رنان يشير إلى أنظمة الذكاء الاصطناعي المستقبلية التي يمكن استخدامها لأغراض متعددة، بل وحتى تتمتع بقدرات مماثلة للبشر. وقد كانت أوبن أيه آي صريحة حول هدفها في تحقيق الذكاء العام الاصطناعي. ولهذا السبب، لا يكترث ألتمان لوجود منافسة بين دال-إي 2 وعدد آخر من الأدوات المماثلة، والتي يتميز بعضها بأنه مجاني. ويقول: "نحن نسعى إلى تحقيق الذكاء العام الاصطناعي، لا بناء برامج لتوليد الصور، وهذا البرنامج جزءٌ من خريطة منتجات شاملة، وهو عنصر صغير من قدرات الذكاء العام الاصطناعي في المستقبل".
إنه تصريح متفائل على الأقل، فالكثير من الخبراء يعتقدون أن الذكاء الاصطناعي الحالي لن يصل إلى هذا المستوى على الإطلاق. فمن ناحية الذكاء الأساسي، فإن نماذج تحويل النصوص إلى صور ليست أكثر ذكاءً من أنظمة الذكاء الاصطناعي التي تولد النصوص، والتي تعتمد عليها هذه النماذج. فالأدوات مثل جي بي تي 3 وبالم (PaLM) من جوجل لا تقوم عملياً سوى بإعادة تركيب أنماط النصوص التي استمدتها من مليارات المستندات التي تدربت عليها. وعلى نحو مماثل، يقوم دال-إي وستيبل ديفيوجن بإعادة إنتاج العلاقات بين النص والصور، والموجودة في المليارات من الأمثلة على الإنترنت.
وعلى الرغم من أن النتائج مذهلة، فإن مجرد تمعن دقيق يكفي لتحطيم كل تلك الأوهام. في الواقع، فإن تلك النماذج ترتكب أخطاءً فادحة في عبارات أساسية وبسيطة، فعند كتابة ’salmon in a river‘ (سمك سلمون في النهر) ستنتج صورة شرائح سمك مقطعة تطفو على سطح الماء، وعند كتابة ’a bat flying over a baseball stadium‘ (خفاش يطير فوق ملعب بيسبول) ستنتج صورة حيوان ثديي طائر وعصا خشبية. ويعود هذا إلى كون هذه النماذج مبنية على تكنولوجيا لم تقترب حتى من فهم العالم كما يفهمه البشر، أو حتى معظم الحيوانات.
وعلى الرغم من هذا، فإن نجاح هذه النماذج في تعلم حيل أكثر تعقيداً ليس سوى مسألة وقت لا أكثر. يقول كوك: "يقول الناس إن هذه الأنظمة ليست جيدة جداً، وبالطبع، فهم محقون. ولكنها ستصبح أكثر براعة بعد إنفاق 100 مليون دولار".
هذه هي مقاربة أوبن أيه آي دون شك.
يقول ألتمان: "نحن نعرف منذ الآن كيف نضاعف قدرة هذا النظام عشر مرات، وندرك أنه أخفق في بعض المهام التي تتطلب تفكيراً منطقياً. وسنقوم بإعداد قائمة من النقاط التي يجب معالجتها، ومن ثم سنبني نسخة جديدة تتضمن إصلاحات لجميع المشكلات الحالية".
إذا كانت الادعاءات حول الذكاء والفهم مبالغاً فيها، فماذا عن الابتكار؟ يعتبر البشر أن الفنانين وعلماء الرياضيات ورواد الأعمال وأطفال رياض الأطفال ومعلميهم أمثلة نموذجية عن الابتكار. ولكن العثور على القاسم المشترك بينهم أمر صعب.
فبالنسبة للبعض، تعتبر النتيجة أهم شيء. على حين يقول آخرون إن طريقة بناء الأشياء، ووجود نية محددة في تلك العملية، هي الأهم.
ويعتمد كثيرون على التعريف الذي وضعته مارغريت بودين، وهي من أهم باحثي الذكاء الاصطناعي والفلاسفة في جامعة سوسيكس في المملكة المتحدة، والذي يتلخص في ثلاثة معايير أساسية: حتى تكون الفكرة مبتكرة، يجب أن تكون جديدة، ومفاجئة، وقيّمة.
اقرا أيضاً: لماذا لم يصمد أحدث النماذج اللغوية الكبيرة من ميتا على الإنترنت أكثر من 3 أيام؟
أما إذا أردنا تجاوز المعايير، فالفكرة المبتكرة في أغلب الأحيان تعبّر عن نفسها بمجرد رؤيتها. ويصف الباحثون في الحقل المعروف باسم الابتكار الحاسوبي عملهم بأنه يتلخص باستخدام الحواسيب لإنتاج نتائج تعتبر مبتكرة إذا ما قام البشر بإنتاجها بمفردهم.
ولهذا، فإن سميث تؤيد، وبسرور، وصف هذا النوع الجديد من النماذج التوليدية بالابتكارية، على الرغم من غبائها الواضح. وتقول: "من الواضح أن هذه الصور تتضمن مسحة ابتكارية لا تخضع لأي تحكم بشري، وغالباً ما تكون نتيجة تحويل النص إلى صورة مفاجئة وجميلة".
أما ماريا تيريزا لانو، والتي تدرس الإبداع الحاسوبي في جامعة موناش في ميلبورن، فهي تؤيد وجهة النظر بأن نماذج تحويل النصوص إلى صور تمثّل توسيعاً للتعاريف السابقة. ولكن لانو لا تعتقد أنها إبداعية. فعند استخدام هذه البرامج بكثرة، تبدأ النتائج بالتكرار، كما تقول. وهذا يعني أنها لا تحقق بعضاً من معايير بودين، أو حتى جميعها. وهو ما يمكن أن يصبح نقطة ضعف جوهرية في هذه التكنولوجيا. فنماذج تحويل النصوص إلى صور مصممة بحيث تطلق صوراً جديدة تشبه المليارات من صور موجودة مسبقاً. ومن المرجح أن التعلم الآلي لن ينتج سوى صور تحاكي ما تعرض له من قبل.
قد لا يكون هذا أمراً مهماً بالنسبة للرسومات الحاسوبية. فقد بدأت شركة أدوبي (Adobe) مسبقاً بالعمل على إدماج تحويل النص إلى صورة ضمن برنامجها فوتوشوب (Photoshop)، كما أن بليندر (Blender)، وهو البديل مفتوح المصدر لفوتوشوب، يتضمن ستيبل ديفيوجن كبرنامج مساعد. وتعمل أوبن أيه آي، بالتعاون مع مايكروسوفت (Microsoft)، على إضافة عنصر تحكم لتحويل النصوص إلى صور في برنامج أوفيس (Office).

يمكن الشعور بالتأثير الحقيقي من هذا النوع من التفاعل في النسخ المستقبلية من هذه الأدوات المألوفة حالياً، حيث لا تحل الآلات محل الإبداع البشري، بل تحسّنه. تقول لانو: "إن الابتكار الذي نشهده حالياً ينتج عن استخدام هذه الأنظمة، لا عن الأنظمة نفسها"، أي من التفاعل ثنائي الاتجاه بين المستخدم والنظام، والقائم على تعديل الدخل وفق النتيجة، وذلك للحصول على النتيجة المرغوبة.
وهذه النظرة تعبّر عن العديد من الباحثين الآخرين في مجال الإبداع الحاسوبي. فالمسألة لا تقتصر على ما تقوم به هذه الأنظمة، بل كيفية القيام به أيضاً. فتحويل هذه الأنظمة إلى شركاء مبدعين حقيقيين يعني دفعها إلى مستوى أعلى من التحكم الذاتي، ومنحها مسؤولية إبداعية، وتحميلها عبء الإشراف إضافة إلى الإبداع في صناعة المحتوى.
اقرأ أيضاً: ميتا تبني ذكاءً اصطناعياً لغوياً جديداً وضخماً ومتاحاً للجميع مجاناً
وستتحقق بعض النواحي من هذا المفهوم قريباً. فقد قام أحدهم بكتابة برنامج يحمل اسم كليب إنتيروغيتر (CLIP Interrogator)، وهو برنامج يقوم بتحليل الصورة المقدمة له وتوليد تعليمة نصية كفيلة بتوليد المزيد من الصور المماثلة لها. كما بدأ آخرون باستخدام التعلم الآلي لتعزيز التعليمات البسيطة بجمل مصممة لمنح الصورة درجة أعلى من الجودة والدقة، ما يعني عملياً أتمتة هندسة التعليمات المُدخلة، وهي مهمة لم تظهر إلى الوجود إلا منذ عدة أشهر وحسب.
وفي هذه الأثناء، ومع تواصل سيل الصور الجديدة، بدأنا بوضع أساسات أخرى أيضاً. يقول كوك: "لقد تلوثت الإنترنت إلى الأبد بالصور التي ولدها الذكاء الاصطناعي، وستكون الصور التي تم توليدها في 2022 جزءاً من أي نموذج سيتم تصميمه من الآن فصاعداً".
وسيتعين علينا أن ننتظر حتى نحدد التأثيرات بعيدة المدى لهذه الأدوات على القطاعات الإبداعية، وعلى مجال الذكاء الاصطناعي بشكل عام. لقد أصبح الذكاء الاصطناعي التوليدي أداة جديدة للتعبير. ويقول ألتمان إنه يستخدم الصور المولدة الآن في الرسائل الشخصية على غرار استخدام الإيموجي. ويقول: "إن بعض أصدقائي لا يكلفون أنفسهم حتى عناء توليد الصورة، ويكتفون بإرسال التعليمة النصية وحسب".
ولكن نماذج تحويل النصوص إلى صور قد تكون مجرد بداية. ويمكن في نهاية المطاف أن يتم استخدام الذكاء الاصطناعي التوليدي لإنتاج تصاميم لكل شيء جديد، بدءاً من المباني وصولاً إلى الأدوية، أي كنماذج لتحويل التعليمات النصية إلى أي شيء.
يقول نيلسون: "سيدرك الجميع أن هذه التقنية أو الحرفة لم تعد عائقاً أمام الإبداع، وأن كل شيء أصبح متعلقاً بقدرتنا على التخيل فقط".
لقد بدأ استخدام الحواسيب من قبل في عدة صناعات لتوليد أعداد ضخمة من التصاميم المحتملة، والتي يتم اختيار المناسب منها لاحقاً. وستسمح النماذج التي تحول التعليمات النصية إلى أي شيء للمصمم البشري بتحسين عملية التوليد منذ البداية، وذلك باستخدام الكلمات لتوجيه الحواسيب عبر عدد هائل من الخيارات للحصول على نتائج ممكنة، بل ومرغوبة أيضاً.
اقرأ أيضاً: تأثير الذكاء الاصطناعي على الصحافة والإعلام: الفرص والتحديات
تستطيع الحواسيب توليد فضاءات ضخمة من الاحتمالات. وستسمح لنا نماذج تحويل التعليمات النصية إلى أي شيء باستكشاف هذه الفضاءات باستخدام الكلمات.
يقول ألتمان: "أعتقد أن هذه التقنية هي الإرث الحقيقي الذي سنقدمه للمستقبل. وبدءاً من الصور والفيديو والصور، سيصبح كل شيء قابلاً للتوليد في نهاية المطاف. وأعتقد أن هذه التقنية ستصبح منتشرة في كل مكان".