في مسعى من شركة ألفابت -الشركة الأم لجوجل- لتحسين نظام ملاحة مناطيد لون، تعاون فريق مشروع لون مع مجموعة من الباحثين في قسم الذكاء الاصطناعي في جوجل على تطوير نظام ملاحة فعّال قائم على خوارزميات الذكاء الاصطناعي، وتحديداً خوارزميات التعلم المعزَّز العميق.
وفي منشور مدونة قبل أيام، أعلن سالفاتور كانديدو، كبير مسؤولي التكنولوجيا في مشروع لون، أن مناطيد لون يتم توجيهها بالكامل بالاعتماد على نظام ذكاء اصطناعي. ويقود هذا النظام حالياً أسطول مناطيد لون فوق كينيا، حيث أطلقت الشركة أول خدمة إنترنت تجارية بالاعتماد على هذه المناطيد في يوليو الماضي.
التعلم المعزز تقنية واعدة لتطوير مشروع لون
يهدف مشروع لون إلى توفير الاتصال بالإنترنت في المناطق النائية بالاعتماد على مناطيد تحلق في طبقة الستراتوسفير وتعمل بالطاقة الشمسية. وتصل المناطيد إلى ارتفاعات تزيد عن 19.3 كيلومتر فوق سطح الأرض، ويمكن أن تغطي مناطق بنصف قطر 40 كيلومتر. وعلى مدى العقد المنصرم، حسَّنت الشركة من العمر التشغيلي للمناطيد حتى يصل إلى متوسط 150 يوماً، وقد بلغ الرقم القياسي لأطول فترة تشغيل حتى الآن 312 يوماً. وتأمل الشركة بتحسين فترة التشغيل عن طريق تركيب أنظمة تحكم أفضل لتجنب اضطرابات الرياح في الستراتوسفير، التي يمكن أن تتجاوز سرعتها 100 كيلومتراً في الساعة، وتجري باتجاهات مختلفة على ارتفاعات مختلفة.
https://www.youtube.com/watch?v=e_QI5llQrF0
ولهذه الأسباب، كان العاملون في مشروع لون في سعي دؤوب لتطوير أنظمة ذاتية التحكم يمكنها الاضطلاع بمهمة التوجيه الفعال للمناطيد بما يؤمن اتصالاً مستقراً بالإنترنت للأشخاص والمناطق التي تفتقر إليها. ووجدوا -بالتعاون مع باحثي جوجل في مونتريال- أن التعلم المعزز العميق يحمل إمكانات واعدة لتحقيق غايتهم هذه.
يعتبر التعلم المعزز العميق أحد تقنيات التعلم الآلي التي تُمكّن نظاماً ما من التعلم من خلال التجربة والخطأ في بيئة تفاعلية يستفيد فيها النظام من معلومات الاستجابة لإجراءاته وقراراته. وهي التقنية وراء تصميم أنظمة الذكاء الاصطناعي المتطورة لممارسة الألعاب مثل ألفاجو وأوبن إيه آي فايف، وتطوير أنظمة توجيه السيارات ذاتية القيادة، وتطوير الروبوتات الذكية، والأيدي الروبوتية التي تستطيع التلاعب بالأشياء.
وفي حالة مناطيد لون، من الواضح أن السماح للنظام بالتجربة والخطأ على أرض الواقع سيكون مكلفاً للغاية في حال تحطم أحد المناطيد؛ لذلك لجأ باحثو جوجل إلى المحاكاة الحاسوبية لتدريب نظام الملاحة على التحكم في طيران المناطيد. وبذلك تمكن النظام من تحسين أدائه بمرور الوقت قبل نشره وتسليمه دفة قيادة أسطول حقيقي من المناطيد.
ووفقاً لما ذكره كانديدو في منشور المدونة، يعد عمل فريقه أول استخدام فعلي للتعلم المعزز على مستوى العالَم في أنظمة التحكم بالطيران. وقد تم نشر التفاصيل التقنية لكيفية نجاحهم في تطوير هذا النظام وتجربته في مجلة نيتشر ضمن مقالة بعنوان: "الملاحة ذاتية التحكم للمناطيد في طبقة الستراتوسفير باستخدام التعلم المعزز".
اختبار ملاحة الذكاء الاصطناعي على أرض الواقع
على الرغم من نجاح نظام الذكاء الاصطناعي القائم على التعلم المعزّز في عمليات المحاكاة في العالّم الافتراضي، إلا أن أبرز التحديات التي تواجه هذا النوع من الأنظمة يتمثل في الانتقال إلى استخدامه في العالم الحقيقي. ولاختبار الفعالية الحقيقية للنظام، قام فريق لون بإجراء تجربتين على أرض الواقع.
التجربة الأولى: الذكاء الاصطناعي 1 – خوارزمية المهندسين 0
في يوليو من عام 2019، أطلق الباحثون منطادين في سماء البيرو. يتولى نظام الذكاء الاصطناعي -الذي أمضى بضعة أسابيع في التدرب على نظام الملاحة- التحكمَ الكامل في تحليق الأول، بينما تقوم خوارزمية -أمضى مهندسو لون سنوات طويلة في تطويرها وتعديلها وضبطها- قيادةَ المنطاد الآخر.
النتيجة: تفوق نظام الذكاء الاصطناعي بسهولة على خوارزمية المهندسين في البقاء قريباً من جهاز خاص موجود على سطح الأرض ومخصص لقياس إشارات شبكة اتصالات من الجيل الرابع، حتى إن حركة المنطاد الأول المُقاد بالذكاء الاصطناعي كانت أكثر سلاسة من حركة المنطاد الآخر.
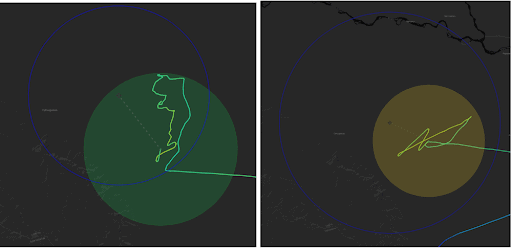
مصدر الصورة: مدونة مشروع لون على موقع وايرد
التجربة الثانية: الذكاء الاصطناعي أكثر كفاءة في استهلاك الطاقة
بعد ذلك، ولتأكيد نتائج التجربة الأولى، قام الباحثون بنشر المناطيد المزودة بنظام الذكاء الاصطناعي في طبقة الستراتوسفير فوق المحيط الهادئ. وهي منطقة أثبت فيها نظام الملاحة التقليدي جدارة مذهلة. وكان الهدف في هذه التجربة هو البقاء ضمن مسافة 50 كم عن موقع محدد. استمرت التجربة لمدة 39 يوماً تولى خلالها نظام التعلم المعزز قيادة وتوجيه مجموعة من المناطيد.
النتيجة: نجح نظام التعلم المعزز في إبقاء المناطيد ضمن النطاق المطلوب لمدة أطول من النظام التقليدي مع استهلاك مقدار أقل من الطاقة. وتكمن أهمية هذا الإنجاز في أنه كلما تمكن منطاد لون من البقاء قريباً من موقع معين، كانت خدمة الإنترنت أكثر استقراراً. ومن ناحية أخرى، فإن توفير الطاقة مسألة جوهرية بالنسبة لهذه المناطيد العاملة بالطاقة الشمسية؛ حيث إن استخدام طاقة أقل في عمليات التوجيه يعني توفير المزيد من الطاقة لتأمين الاتصال بالإنترنت.
خطوات صغيرة للتعلم المعزز وقفزة عملاقة لمشروع لون
يقول كانديدو: "إن النظام الجديد يمثل برهاناً على قدرة التعلم المعزز على التحكم في أنظمة معقدة في العالم الحقيقي". ويرى أن توظيف التعلم المعزز في قيادة وتوجيه مناطيد لون تمثل "خطوات صغيرة بالنسبة للأنظمة القائمة على التعلم المعزز وقفزة عملاقة بالنسبة لمشروع لون". وختم كانديدو بالقول: "لقد انتقلنا من تصميم نظام ملاحة مناطيد لون بأنفسنا إلى جعل الحواسيب تتولى بناء هذا النظام بطريقة قائمة على البيانات. وحتى لو لم تكن تجربتنا تشبه مقدمة لإحدى روايات إسحق عظيموف، فإنها تشكل قصة جيدة تستحق أن نطلق عليها اسم الذكاء الاصطناعي".