
كيف يمكن محاربة البرمجيات الخبيثة؟ بمعنى آخر، كيف نضمن دقة عالية في الجهود الرامية للكشف عن البرامج التي قد يؤدي استخدامها لمخاطر أمنية؟ هذه الأسئلة تتطلب توضيحاً لأمر بسيط، وهو أن المصدر الأساسيّ للمخاطر والتهديدات المتعلقة بالأمن الرقمي مصدرها النصوص البرمجية، ومصدرها حتى نفس البرامج التي نستخدمها ونعتمد عليها في حياتنا اليومية.
كل البرامج التي نستخدمها (سواء كانت تطبيقات الهواتف الذكية أو المتصفحات أو محررات النصوص) مكونة من سطورٍ وتعليمات مكتوبة بإحدى لغات البرمجة، وهذه التعليمات والسطور عبارة عن الآلية التي توضح للمعالج ما الذي نريد القيام به. بما أن البرنامج نفسه عبارة عن سلسلة من السطور والتعليمات المخصصة لتنفيذ أمرٍ ما، ألا يمكن تعديلها قليلاً لتنفيذ أمرٍ آخر؟
أو بطريقة أبسط من ذلك، لنتخيل برنامج مثل المتصفح، الذي يمكن أن يتضمن صلاحيات وصول لأمور مثل الموقع الجغرافي وتشغيل الكاميرا والميكروفون، ألا يمكن لأحدهم -إن تمكن بطريقةٍ ما أن يصل إلى السطور البرمجية المسؤولة عن هذه الأمور (أي الحصول على معلومات الموقع الجغرافي والتخاطب مع الكاميرا)- أن يستغلها لأهدافٍ خبيثة؟ بالطبع، وهذه هي المشكلة الأساسية مع مخاطر الأمن الرقمي، أنه في كل برنامج هناك جزء من التعليمات الخاصة به يمكن استغلالها من قِبل القراصنة والمخترقين، وهو ما يُدعى بالثغرات. ومن ناحيةٍ أخرى، وبحالة تطوير برنامج خبيث بالكامل، فإن الهدف الأساسيّ منه هو جعله يبدو كأنه برنامج موثوق، ولكن مع تضمينه ببعض الخصائص التي تتيح للقراصنة تنفيذ هجماتٍ متنوعة؛ بدءاً من سرقة المعلومات المستخدمة، وصولاً للسيطرة الكاملة على جهازه عبر برمجيات التحكم عن بعد.
هذا الأمر يُصعب من عملية ضمان الرقمي؛ حيث يجب أن تكون هناك وسيلة تضمن مسح البرامج المختلفة لتستطيع تحديد إن كانت هناك سطور وتعليمات تؤدي لنشوء مخاطر رقمية (أي ثغرات)، وإصلاحها من دون الارتباك بينها وبين السطور والتعليمات البرمجية الموثوقة. يمكن تشبيه الأمر بعملية اكتشاف كتلة ورمية ضمن جسم الإنسان؛ حيث يبذل الأطباء جهداً كبيراً لمعرفة إن كانت كتلة خبيثة يجب معالجتها واستئصالها، وإن كانت كتلة حميدة يمكن التعامل معها من دون الاضطرار لإجراءات طبية متقدمة مثل الاستئصال.
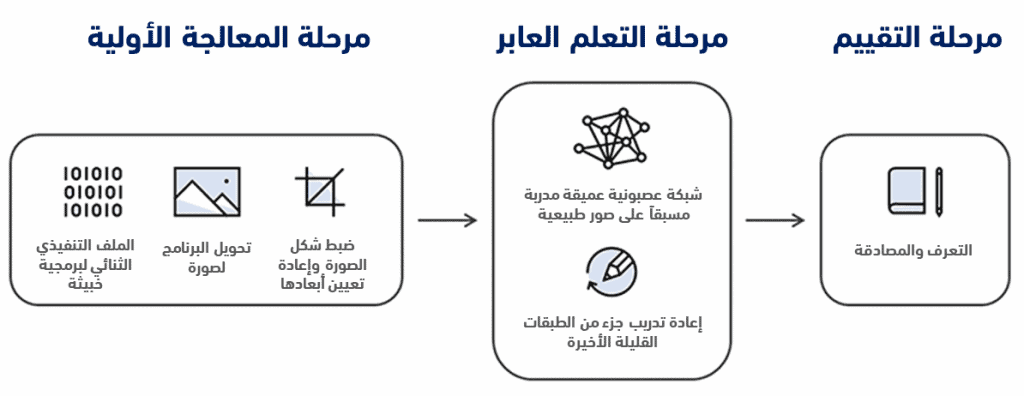
هذا الأمر هو محور تعاون هام بين شركتي مايكروسوفت وإنتل عبر منصةٍ تم تسميتها ستامينا STAMINA، وهي اختصار للجملة التالية Static Malware-as-image Network Analysis؛ حيث تم تطوير هذه المنصة عبر خوارزميات التعلم العميق التي تتميز بقدرتها على التعلم من البيانات المدخلة إليها وتحسين دقتها مع تزايد عمليات التعلم (التعلم العميق هو من طرق التعلم الآلي، الذي بدوره يمثل أحد أشكال الذكاء الاصطناعي).
يتمثل هدف المنصة في إدخال برامج مختلفة (أي سطور وتعليمات برمجية) ومسحها من أجل التعرف على إمكانية وجود تعليمات قد تشكل ثغرات أو تهديدات أمنية، بما يُسهم في تشكيل أنماط تعلم تساعد مستقبلاً في التعرف السريع على البرمجيات الخبيثة. وقد تم التعاون عبر قسم مواجهة المخاطر الرقمية من شركة مايكروسوفت ومخابر شركة إنتل، وهو يهدف لاستخدام التعلم العميق العابر (Deep Transfer Learning) من أجل استغلال طرق وآليات الرؤية الحاسوبية في مجال الكشف عن التهديدات، وقد تم نشر ورقة مرجعية تشرح مفهوم المنصة وآلية عملها لكشف البرمجيات الخبيثة بشكلٍ مفصل.
كيف يتم ذلك؟ عملت الشركتان على تطوير آليةٍ مبتكرة تقوم على تحويل البرمجيات الخبيثة إلى صورٍ رمادية، وهذا يعني أن كل صورة ستمتلك تدرجاً لونياً يبدأ من 0 وحتى 255، بحيث تمثل البيكسلات (عناصر الصورة) التي تمتلك قيمة 0 اللون الأسود والبيكسلات التي تمتلك قيمة 1 اللون الأبيض، كما أن أبعاد الصورة الرمادية الناتجة تتناسب مع حجم البرنامج المدخل، وأخيراً تم تنفيذ عملية إعادة تعيين لحجم الصور؛ وذلك لأن البرمجيات الضخمة قد ينتج عنها صور ذات أبعاد كبيرة جداً، وبحسب إنتل ومايكروسوفت، فإن عملية إعادة التعيين لم تؤثر سلباً على نتائج عمل الخوارزمية ككل، ولو أنها انطوت على بعض الآثار السلبية في بعض الحالات.
ما الهدف من تحويل برنامج ما إلى صورة؟ يتكون الملف التنفيذي الخاص بأي برنامج (الذي يكون عادةً بصيغة exe) من التعليمات الفعلية المكتوبة بلغة الآلة التي يستطيع المعالج تنفيذها بشكلٍ مباشر، وعندما نقول لغة الآلة، فإن المقصد هنا هو سلاسل البتات الرقمية (الأصفار والواحدات) التي تشكل وحدة تمثيل المعلومات في الحواسيب. التعامل مع سلاسل طويلة من الأصفار والواحدات بهدف اكتشاف أنماط معينة ضمنها سيكون أمراً صعباً، بينما إعادة تمثيلها لتشكل صوراً رمادية سيجعل عملية اكتشاف أنماط مشتركة أمراً أسهل.
مصدر الصورة: مايكروسوفت وإنتل | تعريب: إم آي تي تكنولوجي ريفيو العربية
استثمرت مايكروسوفت قاعدة البيانات الضخمة التي تمتلكها، والمتعلقة بالبرمجيات الخبيثة والتهديدات الرقمية المختلفة. وبلغة الأرقام، تم استخدام 2.2 مليون ملف كقاعدة بيانات للمنصة الجديدة، وتم استخدام 60% من البرمجيات الخبيثة المعروفة من أجل تدريب خوارزمية التعلم العميق الخاصة بمنصة ستامينا، ومن ثم تم استخدام 20% من الملفات من أجل التحقق من كفاءة الخوارزمية، وأخيراً تم استخدام الـ 20% الأخيرة من أجل عمليات تجريب واختبار المنصة، وتمثلت النتائج في تحقيق نسبة تعرّفٍ صحيح على البرمجيات الخبيثة تساوي 99%. وبحسب الدراسة المنشورة، فإن هذه النتائج تمثل دافعاً وحافزاً كبيرين من أجل استخدام هذا النمط من الخوارزميات في التعرف على البرمجيات الخبيثة أو الثغرات ضمن التعليمات والسطور البرمجية في البرامج المختلفة.
لا يمثل الخبر الجديد انتصاراً كاملاً على البرمجيات الخبيثة، فعلى الرّغم من إشارة مايكروسوفت إلى أن منصة ستامينا أظهرت قدرةً أعلى على التنقيب في تفاصيل البرامج بهدف اكتشاف التهديدات المحتملة بالمقارنة مع الطرق التقليدية المعتمدة على مسح قواعد بيانات الوصفية (metadata)، إلا أنها تمتلك محدودية تتعلق بحجم البرامج؛ ففي حالة البرامج الضخمة والكبيرة سيكون هنالك عدد ضخم من البيانات الرقمية التي يجب تحويلها إلى صور، وبالتالي فإن ضغطها بصيغة JPEG ومن ثم إعادة تعيينها قد يؤدي لخسارة بيانات هامة تسهم في تخفيض دقة عملية التعرف على البرمجيات الخبيثة، وفي حالات مثل هذه، فإن الطرق التقليدية لا تزال أفضل من طريقة مايكروسوفت وإنتل الجديدة.
وأخيراً، لم توفر شركتا إنتل ومايكروسوفت معلومات واضحة عن مجالات استخدام منصة ستامينا ونوع المنتجات التي سيتم تضمينها فيها؛ فهل ستقوم مثلاً مايكروسوفت باستثمار قدرات منصة ستامينا لتعزيز كفاءة برنامج الحماية الافتراضية ويندوز ديفندر؟ أم أنها ستتجه إلى استخدامها في خدماتها السحابية فقط؟ أم أنه سيتم طرحها كميزة مدفوعة ضمن حزم خدماتها المختلفة؟ لا تزال هذه الأسئلة من دون إجابة.