تمثل الشبكات العصبونية القلبَ البرمجي للتعلم العميق، وعلى الرغم من انتشارها الواسع، فما زال فهمنا لها سطحياً. وقد اكتفى الباحثون بدراسة خصائصها الواضحة من دون أن يفهموا فعلياً سبب عملها بهذه الطريقة.
والآن، قطع بحث جديد من إم آي تي خطوة كبيرة نحو الإجابة عن هذه الأسئلة، وأثناء هذا العمل أحرز الباحثون اكتشافاً بسيطاً ولكنه هام أيضاً، وهو أننا كنا نستخدم شبكات عصبونية أكبر بكثير مما نحتاجه فعلياً، وفي بعض الأحيان، فإن هذه الشبكات أكبر من حاجتنا بعشر مرات أو حتى مائة مرة، ولهذا فإن تدريبها يتطلب من الوقت واستطاعة الحوسبة أكثر مما هو مطلوب بعدة مراتب.
ويمكن أن نعبر عن هذه النتيجة بطريقة أخرى، وهي أنه توجد ضمن كل شبكة عصبونية شبكة أصغر بكثير ويمكن تدريبها لتحقيق نفس أداء الشبكة الأساسية الكبيرة. ولا تمثل هذه النتيجة خبراً مثيراً بالنسبة لباحثي الذكاء الاصطناعي وحسب، بل يحتمل أن تؤدي أيضاً إلى تطبيقات جديدة –قد لا نستطيع استيعاب بعضها حتى الآن- يمكن لها أن تحسِّن حياتنا اليومية، كما سنرى لاحقاً.
ولكن في البداية، لنطلع على طريقة عمل الشبكات العصبونية حتى نعرف كيف يمكن تحقيق هذا الأمر.
مصدر الصورة: جيف كلون/ صورة شاشة (من تعديل آم آي تي تكنولوجي ريفيو العربية)
كيف تعمل الشبكات العصبونية
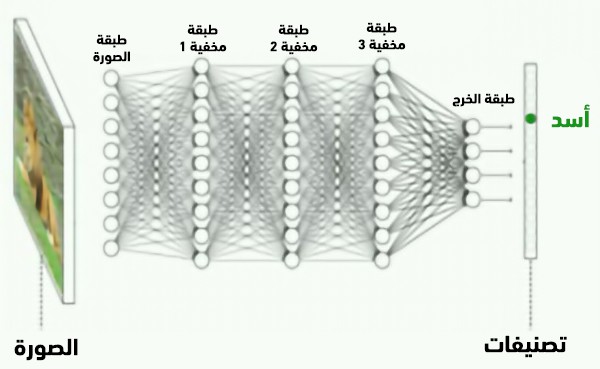
لربما رأيت تمثيلاً للشبكات العصبونية كما في الشكل التوضيحي أعلاه، فهي مؤلفة من عدة طبقات متتالية من العقد الحسابية البسيطة المتصلة معاً لحساب الأنماط في البيانات.
غير أن هذه الوصلات ليست أهم ما في الأمر. فقبل تدريب شبكة عصبونية، تُعطى هذه الوصلات قيماً عشوائية بين الصفر والواحد، وتمثل هذه القيم شدة الوصلات (وتسمى هذه العملية بعملية "التهيئة"). وخلال عملية التدريب -حيث يتم تلقيم الشبكة بمجموعة من صور الحيوانات على سبيل المثال- تقوم بتعديل ومعايرة هذه القيم للشدة، بشكل مشابه لتقوية أو إضعاف الدماغ للوصلات العصبونية المختلفة مع تراكم الخبرة والمعرفة. وبعد التدريب، يتم استخدام القيم النهائية لشدة الوصلات بشكل دائم للتعرف على الحيوانات في الصور الجديدة.
وعلى الرغم من أن مبادئ الشبكات العصبونية مفهومة جيداً، فإن سبب عملها بهذه الطريقة ما زال لغزاً. ولكن عن طريق الكثير من التجارب، لاحظ الباحثون ميزتين للشبكات العصبونية أثبتتا فائدتهما.
الملاحظة الأولى: عندما تتم تهيئة شبكة عصبونية قبل عملية التدريب، يوجد على الدوام احتمال بأن قيم الوصلات العشوائية ستؤدي إلى تشكيلة غير قابلة للتدريب، مما يعني أن الشبكة لن تحقق أداء جيداً مهما كان عدد صور الحيوانات التي تلقمها لها كبيراً، أي أنك ستضطر لإعادة بدئها من جديد بتركيبة جديدة من القيم العشوائية. وكلما كانت الشبكة العصبونية أكبر (من حيث عدد الطبقات والعقد)، كان احتمال حدوث هذا الأمر أقل. وفي حين أن الشبكات العصبونية الصغيرة قابلة للتدريب في واحدة من كل خمس عمليات تهيئة، فإن الشبكات الأكبر قابلة للتدريب في أربع عمليات من أصل خمس. وكما ذكرنا سابقاً فإن سبب هذا الأمر ما زال لغزاً، ولكنه هو ما جعل الباحثين يستخدمون شبكات كبيرة للغاية في مهام التعلم العميق، وذلك لزيادة احتمال تحقيق نموذج ناجح.
الملاحظة الثانية: يؤدي هذا إلى أن الشبكة العصبونية تبدأ عادة بحجم أكبر من المطلوب، وما أن ينتهي تدريبها، تبقى بعض الوصلات فقط قوية، في حين أن الوصلات الباقية تصبح ضعيفة للغاية، لدرجة أنه يمكن في الواقع حذفها، أو "تشذيبها"، دون التأثير على أداء الشبكة.
ولطالما استغل الباحثون لسنوات عديدة هذه الملاحظة الثانية لتقليص الشبكات بعد التدريب لتخفيض ما يحتاجه تشغيلها من الزمن واستطاعة الحوسبة، ولكن لم يفكر أحد في إمكانية تقليص الشبكات قبل التدريب، فقد افترضوا أنه يجب أن تبدأ بشبكة كبيرة للغاية وتقوم بعملية التدريب لتمييز الوصلات الهامة عن غيرها.
غير أن جوناثان فرانكل، وهو طالب دكتوراه في إم آي تي وأحد مؤلفي البحث، شكك في هذا الافتراض، وقال: "إذا كنا فعلياً في حاجة إلى وصلات أقل مما بدأنا به، فلِمَ لا نستطيع ببساطة تدريب شبكات أصغر دون الوصلات الإضافية؟" وقد تبين أنه محق.

مصدر الصورة: جيسون دورفمان، مختبر علوم الحاسوب والذكاء الاصطناعي في إم آي تي
فرضية بطاقة اليانصيب
يتعلق هذا الاكتشاف بحقيقة كون القيم العشوائية التي تعطى لقوة الوصلات في عملية التهيئة ليست عشوائية النتائج في الواقع، حيث إنها تحدد نجاح أو فشل أجزاء الشبكة المختلفة قبل حتى أن يبدأ التدريب، أي أن الوضع الابتدائي يؤثر على الوضع النهائي للشبكة.
بالتركيز على هذه الفكرة، وجد الباحثون أنهم إذا قاموا بتشذيب شبكة كبيرة بعد التدريب، فسوف يتمكنون في الواقع من إعادة استخدام الشبكة الأصغر الناتجة للتدرب على بيانات جديدة والمحافظة على الأداء الجيد، ولكن بشرط إعادة شدة كل وصلة ضمن الشبكة المصغرة إلى قيمتها الابتدائية.
وبناء على هذه النتيجة، فإن فرانكل وشريكه في تأليف البحث، البروفسور في إم آي تي مايكل كاربين، يقترحان ما يطلقان عليه اسم: "فرضية بطاقة اليانصيب". فعند تهيئة شبكة عصبونية بإسناد قيم عشوائية لشدَّات الوصلات، فإن الأمر أشبه بشراء مجموعة من بطاقات اليانصيب، حيث تأمل في أن تكون البطاقة الرابحة بينها، أي التشكيلة الابتدائية التي ستكون سهلة التدريب وتؤدي إلى نموذج ناجح.
وهذا يشرح أيضاً سبب صحة الملاحظة الأولى. فعند البدء بشبكة كبيرة، يكون الأمر أشبه بشراء كمية أكبر من بطاقات اليانصيب، حيث إن هذا لا يعني زيادة القدرة على حل مسألة التعلم العميق، بل يعني ببساطة زيادة احتمال الحصول على تشكيلة جيدة. وما أن تحصل عليها، سيصبح بالإمكان استخدامها مراراً وتكراراً، بدلاً من الاستمرار في سحب بطاقات اليانصيب.
الخطوات التالية
هذا يثير الكثير من الأسئلة.
أولاً، كيف يمكن أن نعثر على البطاقة الرابحة؟ في هذا البحث، اعتمد فرانكل وكاربين على مقاربة القوة القاسية (Brute Force) (أي تجريب جميع الاحتمالات الممكنة) لتدريب وتشذيب شبكة كبيرة بمجموعة بيانات لاستخلاص البطاقة الفائزة لمجموعة بيانات أخرى. ومن الناحية النظرية، يُفترض أن توجد أساليب أكثر فعالية للعثور على التركيبة الفائزة -أو حتى تصميمها- من البداية.
ثانياً، ما حدود التدريب للتركيبة الفائزة؟ يمكن أن نفترض أن الأنواع المختلفة من البيانات والأنواع المختلفة من مهام التعلم العميق ستتطلب تراكيب مختلفة.
ثالثاً، إلى أية درجة يمكن أن نصغر الشبكة العصبونية بحيث نحافظ على الأداء الممتاز؟ وقد وجد فرانكل أنه يمكن -بتكرار عملية التدريب والتشذيب- تصغير الشبكة الابتدائية، وبشكل موثوق، إلى ما بين 10% و20% من حجمها الأصلي، ولكنه يعتقد أن من الممكن تحقيق تصغير إضافي أيضاً.
وقد بدأت الكثير من الفرق البحثية ضمن أوساط الذكاء الاصطناعي بمتابعة البحث في هذا الموضوع. فقد لمّح باحث من برينستون مؤخراً إلى نتائج تخص بحثاً مقبلاً يتمحور حول السؤال الثاني. كما قام فريق في أوبر بنشر بحث جديد حول عدة تجارب لدراسة طبيعة بطاقات اليانصيب الافتراضية تلك. وقد توصلوا إلى نتيجة مفاجئة، وهي أن التركيبة الفائزة قادرة على تحقيق أداء أفضل بكثير من الشبكة الأصلية الكبيرة غير المدربة قبل البدء بأي تدريب، أي أن تشذيب الشبكة لاستخلاص التركيبة الفائزة يمثل بحد ذاته طريقة تدريب هامة.
نعيم الشبكات العصبونية
تخيل فرانكل مستقبلاً حيث سيتمتع الوسط البحثي بقاعدة بيانات مفتوحة المصدر لجميع التشكيلات المختلفة التي وجدها الباحثون، مع توصيفات للمهام التي تستطيع أداءها بشكل جيد، وهو يُسمي هذا الوضع مازحاً: "نعيم الشبكات العصبونية". ويعتقد فرانكل أن هذا سيؤدي إلى إحداث تسارع كبير ونشر للديمقراطية في أبحاث الذكاء الاصطناعي، وذلك عن طريق تخفيض كلفة التدريب وسرعته، وبالسماح لمن لا يستطيعون استخدام مخدمات عملاقة للبيانات بإجراء العمل مباشرة على حواسيب محمولة صغيرة أو حتى هواتف خليوية.
ويمكن أن يؤدي هذا أيضاً إلى تغيير طبيعة تطبيقات الذكاء الاصطناعي؛ فإذا تمكنت من تدريب شبكة عصبونية بشكل محلي على أداتك الخاصة بدلاً من فعل ذلك في السحابة الإلكترونية، يمكنك عندئذ أن تحسن من سرعة عملية التدريب وتقدم حماية أفضل للبيانات. وعلى سبيل المثال، يمكن أن نتخيل جهازاً طبياً يعتمد على التعلم الآلي، ويمكن أن يحسن نفسه عبر الاستخدام المتواصل دون الحاجة إلى إرسال بيانات المرضى إلى مخدمات جوجل أو أمازون.
يقول جيسون يوسينسكي، وهو أحد مؤسسي مختبرات أوبر للذكاء الاصطناعي، وأحد مؤلفي البحث الذي قدمته أوبر: "نحن نصطدم دائماً بحدود ما يمكننا تدريبه، أي أكبر الشبكات العصبونية التي يمكن أن تتسع على وحدة معالجة رسومية أو أطول فترة انتظار ممكنة قبل الحصول على نتائج". وإذا تمكن الباحثون من العثور على طريقة لتحديد التركيبات الفائزة من البداية، فسوف يؤدي هذا إلى تقليص حجم الشبكات العصبونية عشر مرات أو حتى مائة مرة، مما سيؤدي إلى فتح المجال أمام احتمالات جديدة واستخدامات ممكنة جديدة.