
طورت شركة أنثروبيك (Anthropic) للذكاء الاصطناعي طريقةً للنظر داخل نموذج لغوي كبير ومراقبة ما يفعله في أثناء توصله إلى الإجابة، ما يكشف عن رؤى جديدة رئيسية حول كيفية عمل هذه التكنولوجيا. الخلاصة: إن النماذج اللغوية أغرب مما كنا نظن.
يقول عالم الأبحاث في الشركة، جوشوا باتسون، إن فريق أنثروبيك فوجئ ببعض الحلول غير البديهية التي يبدو أن النماذج اللغوية الكبيرة تستخدمها لإكمال الجمل، وحل المسائل الرياضية البسيطة، وقمع الهلوسة، وغير ذلك.
النماذج اللغوية الكبيرة تعمل بطرق غامضة
ليس سراً أن النماذج اللغوية الكبيرة تعمل بطرق غامضة. نادراً ما نجد تكنولوجيات شائعة الاستخدام -إن وجدت- يحيط بها قدر كبير من الغموض. وهذا يجعل فهم آلية عملها أحد أكبر التحديات المفتوحة في العلوم.
لكن الأمر لا يتعلق بالفضول فحسب. فتسليط بعض الضوء على كيفية عمل هذه النماذج من شأنه أن يكشف عن نقاط ضعفها، ويكشف عن سبب اختلاقها للأشياء وإمكانية خداعها لتخرج عن مسارها. ومن شأنه أن يساعد على حل الخلافات العميقة حول ما يمكن لهذه النماذج فعله بالضبط وما لا يمكنها فعله. وسيظهر مدى جدارة هذه النماذج بالثقة (أو عدم جدارتها).
يصف باتسون وزملاؤه عملهم الجديد في تقريرين نُشرا مؤخراً. يعرض التقرير الأول استخدام أنثروبيك لتقنية تسمى "تتبع الدارات" (circuit tracing)، التي تتيح للباحثين تتبع عمليات اتخاذ القرار داخل نموذج لغوي كبير خطوة تلو الأخرى. واستخدمت أنثروبيك تقنية تتبع الدارات لمراقبة نموذجها اللغوي الكبير المسمى كلاود 3.5 هايكو (Claude 3.5 Haiku) وهو ينفّذ مهام مختلفة. ويشرح التقرير الثاني (بعنوان "دراسة بيولوجيا النموذج اللغوي الكبير" [On the Biology of a Large Language Model]) بالتفصيل ما اكتشفه الفريق عند دراسة 10 مهام على وجه الخصوص.
يقول جاك ميرولو، الذي يدرس النماذج اللغوية الكبيرة في جامعة براون بمدينة بروفيدانس في ولاية رود آيلاند، ولم يشارك في البحث: "أعتقد أن هذا عمل رائع حقاً. إنها خطوة رائعة حقاً إلى الأمام من حيث الأساليب".
تتبع الدارات
تتبع الدارات ليس جديداً في حد ذاته. ففي العام الماضي عمل ميرولو وزملاؤه على تحليل دارة معينة في نسخة من جي بي تي-2 (GPT-2) من شركة أوبن أيه آي (OpenAI) وهو نموذج لغوي كبير قديم أصدرته أوبن أيه آي في عام 2019. لكن أنثروبيك تمكنت الآن من تحليل عدد من الدارات المختلفة بصفتها نماذج أكبر بكثير وأكثر تعقيداً بكثير تنفذ مهام متعددة. يقول ميرولو: "إن أنثروبيك بارعة جداً في دراسة مشكلة ما على نطاق أوسع".
يتفق إيدن بيران، الذي يدرس النماذج اللغوية الكبيرة، مع هذا الرأي، إذ يقول: "إن العثور على دارات القرار في نموذج كبير ومتطور مثل كلاود هو إنجاز هندسي غير بديهي. وهذا يدل على أن دارات القرار تتوسع وقد تكون طريقة جيدة للمضي قدماً في تفسير النماذج اللغوية".
تربط الدارات بين أجزاء -أو مكونات- مختلفة من النموذج. في العام الماضي، تمكنت أنثروبيك من تحديد مكونات معينة داخل كلاود تتوافق مع مفاهيم العالم الحقيقي. بعضها كان محدداً، مثل "مايكل جوردان" أو "الخضرة"؛ والبعض الآخر كان أكثر غموضاً، مثل "الصراع بين الأفراد" وبدا أن أحد المكونات يمثّل جسر البوابة الذهبية (الذي يرمز إلى الإبداع والعزيمة الأميركية). وقد وجد باحثو أنثروبيك أنهم إذا رفعوا مستوى هذا المكون، يمكن جعل كلاود يتعرف على نفسه ليس بصفته نموذجاً لغوياً كبيراً، بل نموذجاً للجسر المادي نفسه.
يعتمد العمل الأخير على هذا البحث وعلى عمل آخرين، بما في ذلك شركة جوجل ديب مايند (Google DeepMind)، للكشف عن بعض الروابط بين المكونات الفردية. سلاسل المكونات هي المسارات بين الكلمات المُدخلة في كلاود والكلمات التي تصدر منه.
يقول باتسون: "هذه الاكتشافات مجرد غيض من فيض. ربما نحن ننظر إلى جزء صغير مما يحدث، ولكن هذا يكفي بالفعل للتعرف على بنية مذهلة".
اقرأ أيضاً: 4 أدوات ذكاء اصطناعي لتحويل الصور إلى نماذج ثلاثية الأبعاد
نمو النماذج اللغوية الكبيرة
يعكف الباحثون في أنثروبيك وأماكن أخرى على دراسة النماذج اللغوية الكبيرة كما لو كانت ظواهر طبيعية وليست برمجيات من صنع الإنسان. ذلك لأن النماذج تخضع للتدريب لا للبرمجة.
يقول باتسون: "إنها تنمو بصورة طبيعية تقريباً. فهي تتخذ شكلاً عشوائياً تماماً في بادئ الأمر، ثم تدربها على هذه البيانات كلها لتنتقل بمرور الوقت من إنتاج مخرجات غير مفهومة إلى القدرة على التحدث بلغات مختلفة وكتابة البرمجيات وطي البروتينات. هناك أشياء مجنونة تتعلم هذه النماذج تنفيذها، لكننا لا نعرف كيف حدث ذلك لأننا لم ندخل في جوهر عملها ونضبط المفاصل الرئيسية".
كل شيء يعتمد على العمليات الرياضية بلا شك، لكنها ليست من النوع الذي يمكننا فهمه ببساطة. يقول باتسون: "إذا اطلعت على البنية التفصيلية لنموذج لغوي كبير، فإن كل ما ستراه هو مليارات الأرقام، أي المتغيرات الوسيطية. هذا لا يوضح شيئاً في الواقع".
تقول أنثروبيك إنها استلهمت نهجها من تقنيات مسح الدماغ المستخدمة في علم الأعصاب لبناء ما تصفه الشركة بأنه نوع من المجهر الضوئي الذي يمكن توجيهه إلى أجزاء مختلفة من النموذج في أثناء تشغيله. تسلط هذه التقنية الضوء على المكونات النشطة في أوقات مختلفة. ويمكن للباحثين بعد ذلك زيادة التركيز على المكونات المختلفة وتسجيل أوقات نشاطها وتوقفها.
خذ على سبيل المثال المكون الذي يتوافق مع جسر البوابة الذهبية. ينشط هذا المكون عندما يُعرض على كلاود نص يسمي الجسر أو يصفه أو حتى نص متعلق بالجسر، مثل "سان فرانسيسكو" أو "جزيرة ألكاتراز". ويكون هذا المكون خاملاً في خلاف ذلك.
قد يتوافق مكون آخر مع فكرة "الصغر" (smallness)، يقول باتسون: "نحن نتحقق من عشرات الملايين من النصوص ونرى أن المكون ينشط عند ورود كلمة 'صغير' (small)، وكلمة 'ضئيل' (tiny)، وكلمة 'صغير' ذات الأصل الفرنسي (petite)، والكلمات المتعلقة بالصغر عموماً، والأشياء الصغيرة جداً، مثل الكشتبانات (thimbles)، أي أننا نركز على الأشياء الصغيرة فحسب".
بعد تحديد المكونات الفردية، تعمل أنثروبيك على تتبع المسار داخل النموذج الذي يُظهر ترابط المكونات المختلفة بعضها مع بعض. يبدأ الباحثون من المرحلة الأخيرة، انطلاقاً من المكون أو المكونات التي أدت إلى الإجابة النهائية التي يقدمها كلاود رداً على الاستعلام. ثم يتتبع باتسون وفريقه المسار العكسي لهذه السلسلة.
سلوك غريب
إذاً: ماذا وجدوا؟ درست أنثروبيك 10 سلوكيات مختلفة لدى كلاود، حيث تضمن أحدها استخدام لغات مختلفة. هل لدى كلاود جزء يتحدث الفرنسية وجزء آخر يتحدث الصينية، وهكذا دواليك؟
وجد الفريق أن كلاود استخدم مكونات مستقلة عن أي لغة للإجابة عن سؤال أو لحل مشكلة، ثم اختار لغة معينة عندما قدم الإجابة. فإذا سألت كلاود: "ما هو عكس كلمة صغير؟" بالإنجليزية والفرنسية والصينية، فسيستخدم أولاً المكونات المحايدة لغوياً المتعلقة بـ "الصغر" و"الأضداد" للتوصل إلى إجابة. عندها فقط سيختار لغة معينة ليجيب بها، وهذا يشير إلى أن النماذج اللغوية الكبيرة يمكن أن تتعلم الأشياء بلغة معينة وتطبقها باستخدام لغات أخرى.
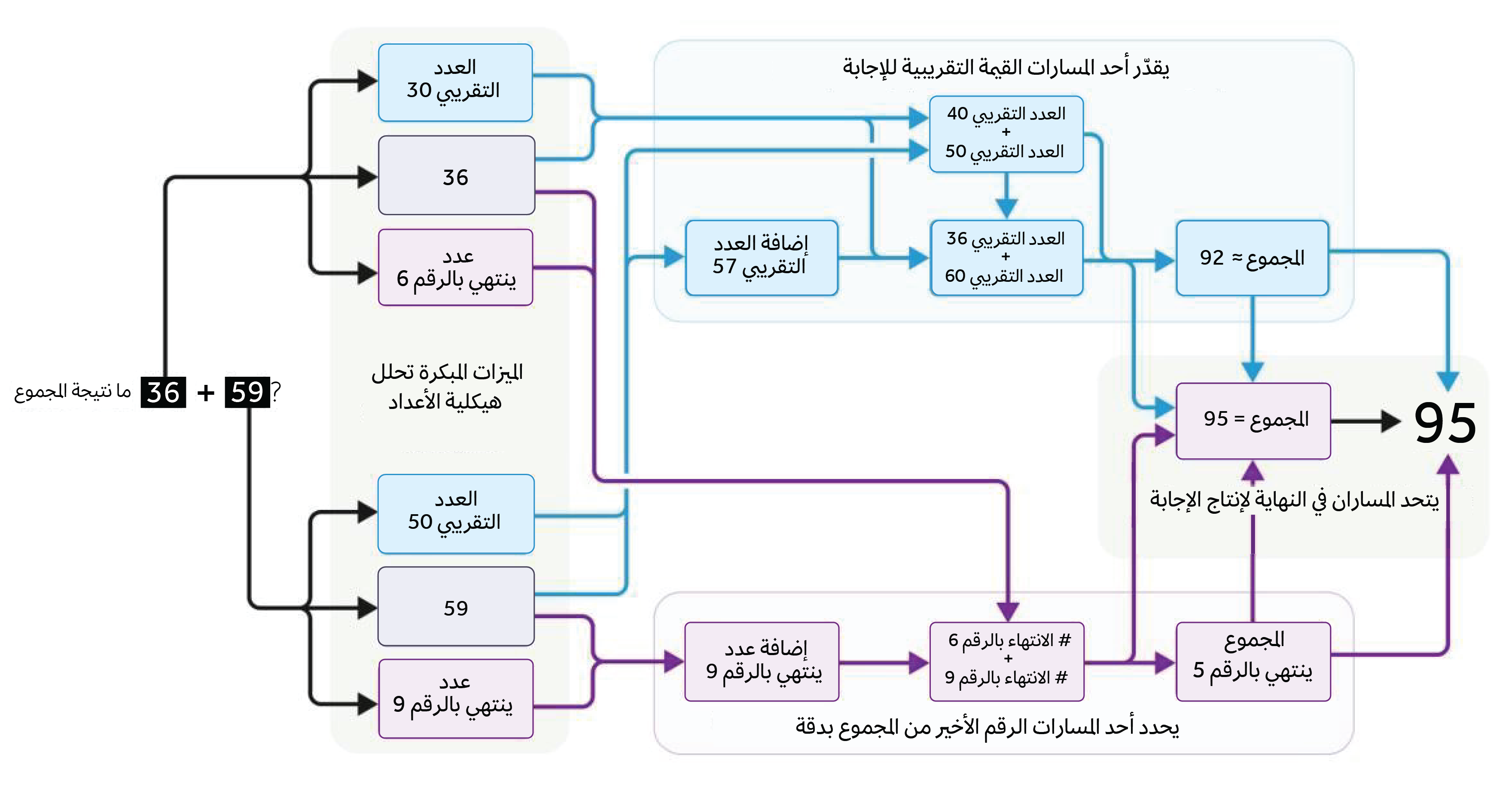
درست أنثروبيك أيضاً الطرق التي اتبعها كلاود في حل المسائل الرياضية البسيطة. ووجد الفريق أن النموذج يبدو أنه طوّر استراتيجيات داخلية خاصة به تختلف عن تلك التي صادفها ربما في بيانات التدريب الخاصة به. إذا طلبت من كلاود أن يجمع العددين 36 و59 فسيمر النموذج بسلسلة من الخطوات الغريبة، بما في ذلك جمع مجموعة مختارة من القيم التقريبية أولاً (جمع العدد التقريبي 40 مع العدد التقريبي 60، وجمع العدد التقريبي 57 مع العدد التقريبي 36). وفي نهاية العملية التي ينفذها، يتوصل إلى القيمة التقريبية 92. وفي الوقت نفسه، يركز تسلسل آخر من الخطوات على الرقمين الأخيرين، 6 و9، ويحدد أن الإجابة يجب أن تنتهي بالرقم 5. وعند مقاطعة هذه المعلومات مع القيمة التقريبية 92، نحصل على الإجابة الصحيحة وهي 95.
ومع ذلك، إذا سألت كلاود بعد ذلك عن كيفية التوصل إلى تلك الإجابة، فسيقول لك شيئاً مثل: "لقد جمعت الآحاد (6+9=15)، وحملت الرقم 1، ثم جمعت العشرات (3+5+1=9)، فنحصل على 95". بعبارة أخرى، فإنه يعطيك طريقة شائعة موجودة في كل مكان على الإنترنت بدلاً من توضيح ما فعله بالفعل. أجل! إن النماذج اللغوية الكبيرة غريبة الأطوار. (ولا يمكن الوثوق بها).
هذا دليل واضح على أن النماذج اللغوية الكبيرة ستقدم مبررات لما تفعله لا تعكس بالضرورة ما فعلته بالفعل. لكن هذا ينطبق على البشر أيضاً، يقول باتسون: "إذا سألت أحدهم: 'لماذا فعلت ذلك؟' فسيذكر لك تبريراً معيناً، ولكنه ربما لا يقول الحقيقة. ربما كان جائعاً فقط وهذا ما دفعه إلى فعل ما فعله".
الاعتماد على مخرجات النماذج فقط ليس كافياً
يعتقد بيران أن هذه النتيجة مثيرة للاهتمام على وجه الخصوص. فالعديد من الباحثين يدرسون سلوك النماذج اللغوية الكبيرة من خلال الطلب منها بأن تفسر أفعالها. لكن هذا قد يكون نهجاً محفوفاً بالمخاطر، كما يقول بيران: "مع ازدياد قوة النماذج، يجب تزويدها بحواجز حماية أفضل. أعتقد -وهذا ما يوضحه هذا العمل أيضاً- أن الاعتماد على مخرجات النماذج فقط ليس كافياً".
كانت المهمة الثالثة التي درستها أنثروبيك هي كتابة القصائد الشعرية. أراد الباحثون أن يعرفوا إن كان النموذج يرتجل فعلاً، من خلال التنبؤ بكلمة واحدة في كل مرة. لكنهم وجدوا أن كلاود كان يتعامل مع النص بطريقة استباقية إلى حد ما، واختار الكلمة الواردة في نهاية السطر التالي قبل عدة كلمات.
على سبيل المثال، عندما قدّم الباحثون لكلاود الأمر النصي: "بيت شعري مقفّى: رأى جزرة وكان عليه أن يلتقطها" (A rhyming couplet: He saw a carrot and had to grab it) بالإنجليزية، أجاب النموذج "كان جوعه أشبه بأرنب جائع" (His hunger was like a starving rabbit) ولكن باستخدام المجهر الخاص بهم، اكتشفوا أن كلاود كان قد وصل بالفعل إلى كلمة "أرنب" عندما كان يعالج كلمة "يلتقطها" ثم بدا أنه كتب السطر التالي باستخدام هذه القافية بالفعل (في الإنجليزية الصفة تسبق الموصوف لذا فإن القافية هي "أرنب").
قد يبدو هذا تفصيلاً صغيراً. لكنه يتعارض مع الافتراض الشائع بأن النماذج اللغوية الكبيرة تعمل دائماً من خلال اختيار كلمة واحدة في كل مرة بالتسلسل. يقول باتسون: "لقد أذهلني أسلوب التخطيط في القصائد، فبدلاً من محاولة اختيار القافية في اللحظة الأخيرة بأسلوب منطقي، فإن النموذج يعرف إلى أين يتجه".
يقول ميرولو: "كان الأمر رائعاً بالنسبة لي. إحدى مباهج العمل في هذا المجال هي لحظات كهذه. ربما كانت هناك أدلة صغيرة تشير إلى قدرة النماذج على التخطيط الاستباقي، لكن يبقى السؤال الكبير المطروح حول مدى قدرتها على ذلك مفتوحاً".
أكدت أنثروبيك ملاحظتها بعد ذلك بإيقاف تشغيل المكون المسؤول عن "عالم الأرانب"، فردّ كلاود بعبارة "كان جوعه عادة قوية" (His hunger was a powerful habit). وعندما استعاض الفريق عن المكون المسؤول عن "عالم الأرانب" بالمكون المسؤول عن "الخضرة" (greeness)، رد كلاود بعبارة "ليحررها من خضرة الحديقة" (freeing it from the garden’s green).
كما درست أنثروبيك أيضاً سبب اختلاق كلاود للأشياء في بعض الأحيان، وهي ظاهرة تعرف باسم الهلوسة (hallucination). يقول باتسون: "الهلوسة هي أكثر السمات الطبيعية التي تتمتع بها هذه النماذج، نظراً لأنها مدربة على تقديم الأجزاء المكملة المحتملة. السؤال الحقيقي هو: كيف يمكنك أن تمنعها من فعل ذلك؟".
إن أحدث جيل من النماذج اللغوية الكبيرة، مثل كلاود 3.5 وجيميناي (Gemini) وجي بي تي-4 أو (GPT-4o)، يهلوس بدرجة أقل بكثير من الإصدارات السابقة، وذلك بفضل التدريب اللاحق المكثف (الخطوات التي تحول النموذج اللغوي الكبير الذي جرى تدريبه على الإنترنت إلى بوت دردشة صالح للاستخدام). لكن فريق باتسون فوجئ عندما وجد أن هذا التدريب اللاحق يبدو أنه جعل كلاود يرفض التخمين بصفته سلوكاً افتراضياً. عندما كان يرد بمعلومات خاطئة، كان ذلك بسبب أن مكوناً آخر قد تجاوز المكون المسؤول عن "عدم التخمين" (don’t speculate).
يبدو أن هذا كان يحدث في أغلب الأحيان عندما يتعلق التخمين بشخصية مشهورة أو كيان آخر معروف. يبدو الأمر كما لو أن كمية المعلومات المتاحة دفعت التخمينات إلى الظهور، على الرغم من الإعداد الافتراضي. عندما تجاوزت أنثروبيك مكون "عدم التخمين" لاختبار ذلك، أدلى كلاود بالكثير من التصريحات الكاذبة عن الأفراد، بما في ذلك الادعاء بأن باتسون كان مشهوراً بأنه اخترع مبدأ باتسون (وهو ليس كذلك).
اقرأ أيضاً: شركة أنثروبيك تطوّر «درعاً» لحماية أنظمة الذكاء الاصطناعي من التلاعب والاختراق
الغموض سيد الموقف
نظراً لأننا لا نعرف سوى القليل جداً عن النماذج اللغوية الكبيرة، فإن أي رؤية جديدة متعمقة تعتبر خطوة كبيرة إلى الأمام. يقول بيران: "إن الفهم العميق لكيفية عمل هذه النماذج من الداخل سيمكّننا من تصميم نماذج أفضل وأقوى بكثير وتدريبها".
لكن باتسون يشير إلى أنه لا تزال هناك أوجه قصور خطيرة، إذ يقول: "هناك اعتقاد خاطئ بأننا وجدنا مكونات النموذج كلها أو توصلنا، على سبيل المثال، إلى نظرة شاملة. بعض الأشياء باتت واضحة، لكن هناك أشياء أخرى لا تزال غير واضحة، ناجمة عن خلل في عمل المجهر".
ويستغرق الباحث البشري عدة ساعات لتتبع الإجابات حتى بالنسبة إلى الأوامر النصية القصيرة جداً. والأكثر من ذلك، يمكن لهذه النماذج أن تنفذ عدداً هائلاً من المهام المختلفة، ولم تدرس أنثروبيك حتى الآن إلا 10 منها فقط.
يقول باتسون أيضاً إن هناك أسئلة كبيرة لن يجيب عنها هذا النهج. يمكن استخدام تتبع الدارات لتحليل البنى القائمة داخل نموذج لغوي كبير، لكنه لن يخبرك بكيفية تشكل هذه البنى في أثناء التدريب ولن يخبرك بتفسير ذلك. يقول باتسون: "هذا سؤال عميق لا نعالجه على الإطلاق في هذا العمل".
لكن باتسون يرى في هذا العمل بداية حقبة جديدة يمكن فيها أخيراً إيجاد دليل حقيقي على كيفية عمل هذه النماذج: "ليس علينا أن نطرح أسئلة من قبيل: "هل هذه النماذج تفكر؟ هل تعتمد على الاستدلال؟ هل تحلم؟ هل تحفظ؟ هذه كلها تشبيهات. ولكن إذا كان بإمكاننا أن نعرف بدقة ما يفعله النموذج خطوة بخطوة، فربما لا نحتاج الآن إلى تشبيهات".