
خلال الأعوام الأخيرة، شهد مجال معالجة اللغات الطبيعية (NLP) ثورة من خلال تطوير نماذج لغوية (LMs) مدربة على كميات كبيرة من البيانات النصية، ومن المعروف أن زيادة حجم هذه النماذج اللغوية غالباً ما تؤدي إلى تحسن أدائها في مجموعة واسعة من المهام على نحو يمكن التنبؤ به. ولاحظ الباحثون في مجال الذكاء الاصطناعي أنه عندما يزداد حجم هذه النماذج اللغوية الكبيرة (LLMs) إلى مرحلة معينة، فإن قدرتها على أداء بعض المهام تتحسن بطريقة سريعة وفي قفزات مفاجئة، وأطلق العلماء على هذه الظاهرة اسم القدرات المنبثقة في النماذج اللغوية الكبيرة (Emergent Abilities of Large Language Models).
ما هي القدرات المنبثقة؟
يمكن لنماذج المهام العامة (Task-general models) أن تؤدي مهاماً جديدة لم يتم تضمينها بشكلٍ صريح في بيانات التدريب الخاصة بها. على سبيل المثال، يمكن لنموذج جي بي تي-3 (GPT-3) أن يقوم بعمليات ضرب للأعداد المكونة من رقمين على الرغم من أنه لم يتم تدريبه بشكلٍ صريح على القيام بذلك. لكن الباحثين يشيرون إلى أن هذه القدرة على أداء المهام الجديدة تحدث فقط للنماذج التي تحتوي على عدد معين من المعاملات الوسيطة ويتم تدريبها على مجموعة بيانات كبيرة بما يكفي.
تلقي دراسة نشرها فريقٌ من الباحثين في شركتي جوجل وديب مايند وجامعتي ستانفورد ونورث كارولينا في تشابل هيل، الضوء على هذه الظاهرة وعلى المهام التي يمكن للنماذج اللغوية الكبيرة أن تنجزها عندما تصبح أوسع نطاقاً ويتم تدريبها على المزيد من البيانات.
وتُعرّف الدراسة التي نُشرت في دورية المعاملات في أبحاث التعلم الآلي (Transactions on Machine Learning Research) في شهر أغسطس/ آب الماضي، "القدرات المنبثقة" بأنها "قدرات لا تظهر في النماذج الأصغر نطاقاً لكنها تظهر في النماذج الأوسع نطاقاً؛ وبالتالي لا يمكن التنبؤ بها ببساطة عن طريق استقراء التحسينات في الأداء على النماذج الأصغر نطاقاً". بكلمات أخرى، عندما يتم تصوير القدرات المنبثقة على منحنى الحجم (بحيث يكون المحور س: حجم النموذج والمحور ع: الأداء)، فإنها تُظهر نمطاً واضحاً أو أداء شبه عشوائي في البداية حتى يصل حجم النموذج إلى عتبة معينة، وعندها يرتفع الأداء إلى أعلى بكثير من المعدل العشوائي.
اقرأ أيضاً: ريترو: نموذج لغوي جديد من ديب مايند يستطيع التفوق على نماذج تفوقه حجماً
ورقة علمية نشرت عن انبثاق Emergence لخصائص جديدة في الذكاء الاصطناعي لم تكن متوقعة.
اكتشف العلماء من النظر في نماذج اللغة الكبيرة أنها تتغير وتنبثق منها قدرات لما يكبر حجمها. والغريب أنه لما تكون هذه النماذج أصغر لا تظهر هذه الخصائص، وكأنما هناك شيء يحصل بالداخل، ويصبح الذكاء… pic.twitter.com/rdeuZnw2TA
— Dr. Mohamed Qasem د. محمد قاسم (@mqasem) April 17, 2023
يُعرف هذا التغير النوعي أيضاً باسم المرحلة الانتقالية (phase transition)، وهو "تغيير جذري في السلوك العام لم يكن من الممكن توقعه من خلال فحص الأنظمة ذات النطاق الأصغر".
لا يتم تدريب النماذج الكبيرة بشكلٍ مباشر على امتلاك هذه القدرات، التي تظهر بطرق سريعة وغير متوقعة كما لو كانت تنبثق من العدم، وتتضمن هذه القدرات إجراء العمليات الحسابية والإجابة عن الأسئلة وتلخيص المقاطع وغيرها من القدرات التي تتعلمها النماذج ببساطة من خلال رصد اللغة الطبيعية.
وتقدّم الدراسة العشرات من الأمثلة على القدرات المنبثقة التي تنتج عن توسيع نطاق النماذج اللغوية، ويشير بعض الباحثين إلى أن وجود مثل هذه القدرات يُثير التساؤل عما إذا كانت زيادة الحجم عموماً يمكن أن تزيد قدرات النماذج.
اقرأ أيضاً: أوبن أيه آي تطرح مليون نسخة من نموذجها اللغوي دال إي في الأسواق
أمثلة على القدرات المنبثقة
ما اسم الفيلم الذي تصفه هذه الرموز التعبيرية؟

هذا السؤال الذي يعرضه الكاتب ستيفن أورنيس في مقالة مفصّلة حول القدرات المنبثقة كان واحداً من 204 مهمات تم اختيارها العام الماضي لاختبار قدرة النماذج اللغوية الكبيرة.
جاءت إجابات النماذج البسيطة غير منطقية تماماً، حيث قال أحدها "الفيلم يحكي عن رجل هو رجل هو رجل". أنتجت النماذج متوسطة التعقيد إجابات أفضل، من ضمنها أنه "فيلم الرموز التعبيرية"، لكن النموذج الأكثر تعقيداً أصاب الهدف من أول تخمين: فيلم البحث عن نيمو (Finding Nemo).
ينقل أورنيس عن عالم الحاسوب في جوجل ريسرش (Google Research) إيثان داير، الذي ساعد على ترتيب الاختبار، قوله: "على الرغم من أنني حاولت توقع المفاجأة، فإنني مندهش من الأشياء التي يمكن لهذه النماذج فعلها". توقع علماء الحاسوب أن زيادة الحجم ستعزز الأداء في المهام المعروفة، لكنهم لم يتوقعوا أن تعالج النماذج العديد من المهام الجديدة التي لا يمكن التنبؤ بها.
يعرض عالم الأبحاث في "جوجل برين" ويي تاي، والباحث في شركة "أوبن أيه آي" جايسون وي، وكلاهما مشارك في الدراسة، في الرسم التالي، 3 أمثلة على القدرات المنبثقة: إجراء عمليات حسابية متعددة الخطوات، والنجاح في الامتحانات على المستوى الجامعي، وتحديد المعنى المقصود من كلمة في السياق.
اقرأ أيضاً: هل يمكن للنماذج اللغوية أن تصحح تحيزاتها ذاتياً إذا طلبنا منها ذلك؟
وتشمل النماذج التي أجريت عليها التجربة لامدا (LaMDA) وجي بي تي-3 (GPT-3) وغوفر (Gopher) وتشينتشيلا (Chinchilla) وبالم (PaLM).
وكما يظهر من الرسم، يكون أداء النماذج اللغوية ضعيفاً للغاية حتى عتبة معينة، عندها يبدأ الأداء في الارتفاع المفاجئ.
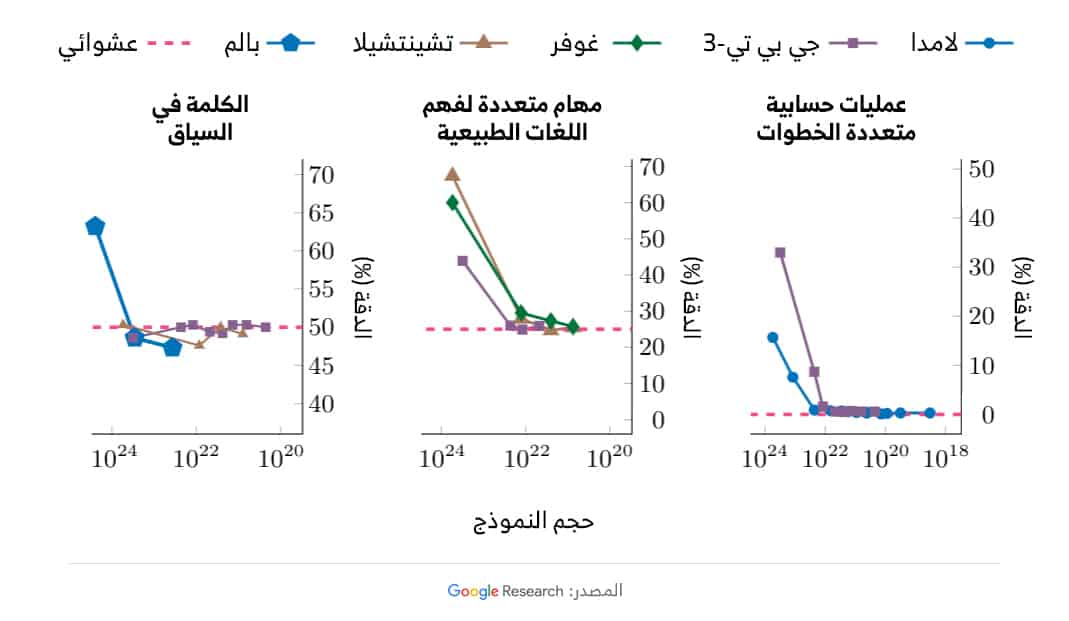
غموض حول سبب هذه الظاهرة
مفهوم الانبثاق (Emergence) في حد ذاته ليس جديداً تماماً، وهو معروف في مختلف العلوم مثل الفلسفة والفيزياء والاقتصاد.
وعلى الرغم من عدم وجود تعريف جامع له، فإنه عادة ما يشير إلى الوضع الذي يُظهر فيه النظام خصائص لا تمتلكها عناصره الفردية في حد ذاتها. على سبيل المثال، سلوكيات أو قدرات لا تظهر إلا من خلال تفاعل الأجزاء الفردية للنظام.
في مجال الذكاء الاصطناعي، يرجع الاهتمام بالنماذج اللغوية الكبيرة إلى قدراتها المذهلة على إنتاج نصوص طويلة متماسكة والانخراط في المحادثات على نحو كان يعتقد دائماً أنه أكبر من قدرات الحواسيب، لكن لا يزال هناك الكثير لنتعلمه حول الطريقة التي تعمل بها هذه النماذج اللغوية، ومن ضمن ما ينبغي أن تعلمه الأسباب التي تؤدي إلى هذه الظاهرة.
يشير الباحثون إلى تفسيرات مختلفة لظهور القدرات المنبثقة في النماذج اللغوية الكبيرة. ومع ذلك، فقد خلصوا إلى أنه لا يمكن تفسيرها بشكلٍ قاطع. فبالإضافة إلى زيادة حجم النموذج ومجموعات البيانات، يمكن في بعض الحالات للنماذج الأصغر ذات البنى الأكثر حداثة أو البيانات الأعلى جودة أو إجراءات التدريب المحسّنة تطوير قدرات مماثلة. لذا، فإن الحجم ليس العامل الوحيد الذي يؤدي لانبثاق قدرة جديدة.
اقرأ أيضاً: ميتا تنافس تشات جي بي تي بنموذج ذكاء اصطناعي يتحدث 20 لغة
تقول عالمة الحاسوب في جامعة براون، إيلي بافليك، إن النتائج الحديثة تشير إلى وجود احتمالين على الأقل لسبب حدوث الانبثاق؛ الأول، كما تقترح المقارنات بالأنظمة البيولوجية، هو أن النماذج الأكبر تكتسب قدرات جديدة تلقائياً، مضيفة: "ما نأمله جميعاً هو أن يكون هناك بعض التحول الجوهري الذي يحدث عندما يزيد حجم النماذج". الاحتمال الآخر الأقل إثارة، بحسب بافليك، هو أن ما يبدو أنه قدرة منبثقة قد يكون تتويجاً لعملية داخلية مدفوعة بالإحصاءات.
قد تكون النماذج اللغوية الكبيرة تتعلم الاستدلال الذي لا يمكن للنماذج التي تحتوي على معاملات وسيطة أقل عدداً أو بيانات أقل جودة أن تتعلمه.
يرجع الغموض المحيط بهذه الظواهر إلى حقيقة أنها لم تتم دراستها بشكل كافٍ سوى مؤخراً.
يقول عالم الحاسوب في جامعة ستانفورد والمشارك في الدراسة ريشي بوماساني: "لم تتم أبداً مناقشة إمكانية أن تفعل النماذج اللغوية مثل هذه الأشياء في أي أدبيات أعرفها".
يعد تحديد القدرات المنبثقة خطوة أولى نحو فهم هذه الظاهرة وتأثيرها المحتمل على قدرات النماذج المستقبلية، كما يمكنها أن تساعد العلماء على الاستفادة من الفوائد المحتملة للنماذج والحد من مخاطرها.
اقرأ أيضاً: ماذا لو نفدت البيانات اللازمة لتدريب نماذج الذكاء الاصطناعي اللغوية؟
ويرى الباحثان تاي ووي أن ثمة أسئلة مهمة لا تزال تحتاج إلى إجابة، من ضمنها: لماذا تؤدي زيادة حجم النموذج إلى إطلاق هذه القدرات المنبثقة؟ وهل يمكن إطلاقها عبر طرق أخرى بخلاف زيادة الحجم -عبر تقنيات تدريب أفضل مثلاً- نظراً لأن الموارد الحاسوبية مكلفة؟ وهل هناك مخاطر جديدة قد تظهر في النماذج المستقبلية؟
إذا أثارت هذه الظاهرة اهتمامك، يمكنك الاطلاع على القائمة الكاملة للقدرات المنبثقة التي تم اكتشافها حتى الآن، والتي قام الباحث جيسون وي بتجميعها لأغراض بحثية، عبر هذا الرابط.