يمكن أن يصبح فهم ألغاز أنظمة الذكاء الاصطناعي أسهل بفضل تعديل طفيف على طريقة عمل العصبونات الاصطناعية في الشبكات العصبونية.
لقد نجحت العصبونات الاصطناعية –التي تمثّل العناصر الأساسية في بناء الشبكات العصبونية العميقة- في البقاء دون تغيير يستحق الذكر على مدى عقود كاملة من الزمن. وعلى حين تمنح هذه الشبكات الذكاء الاصطناعي المعاصر قدراته الهائلة، فإنها أيضاً غامضة وعصيّة على الفهم.
تعمل العصبونات الاصطناعية الحالية، على غرار تلك المستخدَمة في النماذج اللغوية الكبيرة مثل جي بي تي 4 (GPT-4)، من خلال استقبال عدد كبير من المدخلات، وجمعها معاً، وتحويل المجموع إلى ناتج بالاعتماد على عملية رياضية أخرى ضمن العصبون. تتألف الشبكات العصبونية من تراكيب مختلفة من هذه العصبونات، وقد يكون من الصعب فك رموز عملها مجتمعة.
اقرأ أيضاً: كيف يساعد الذكاء الاصطناعي على تمكين الشبكات الذكية للطاقة؟
طريقة جديدة في تركيب العصبونات الاصطناعية
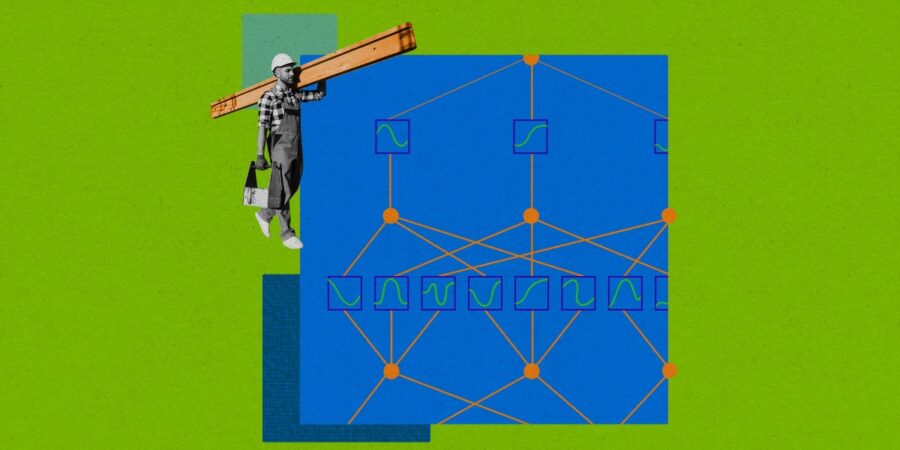
لكن الطريقة الجديدة في تركيب العصبونات مختلفة بعض الشيء. وتؤدي هذه الطريقة إلى تبسيط بعض من تعقيدات العصبونات الحالية ونقلها إلى خارج العصبونات في الوقت نفسه. داخلياً، تعمل العصبونات الجديدة ببساطة على جمع مدخلاتها وإنتاج مخرجات، دون الحاجة إلى العملية الخفية الإضافية. تحمل الشبكات المكونة من هذه العصبونات اسم شبكات كولموغوروف-أرنولد (Kolmogorov-Arnold Networks)، أو اختصاراً "كان" (KAN)، تيمناً بعالمي الرياضيات الروسيين الذين كانت أعمالهما مصدراً للإلهام في تصميم هذه العصبونات.
يمكن لعملية التبسيط هذه، التي درستها بالتفصيل مجموعة بقيادة باحثين في معهد ماساتشوستس للتكنولوجيا (إم آي تي)، أن تسهّل فهم سبب إنتاج الشبكات العصبونية لمخرجات معينة، وتساعد في التحقق من قراراتها، وحتى التحقق من التحيز. تشير الأدلة الأولية أيضاً إلى أنه كلما زاد حجم شبكات "كان"، زادت دقتها بوتيرة أسرع مقارنة بالشبكات المبنية من عصبونات تقليدية.
يقول الباحث الذي يدرس أسس التعلم العميق في جامعة نيويورك، أندرو ويلسون، إنه "عمل مثير للاهتمام. ومن الرائع أن نجد البعض يسعى إلى إعادة النظر جذرياً في تصميم هذه الشبكات".
أنظمة "كان"
جرى اقتراح عناصر أنظمة "كان" الأساسية في التسعينيات من القرن الماضي، وقد استمر الباحثون ببناء إصدارات بسيطة من تلك الشبكات. غير أن الفريق الذي يقوده معهد إم آي تي قرر المضي قدماً بهذه الفكرة إلى أبعد من ذلك، حيث أظهر كيفية بناء شبكات "كان" بحجم أكبر وتدريبها، وأجرى اختبارات عملية عليها، وأجرى تحليلاً لعدد من هذه الشبكات لإثبات قدرة البشر على تفسير قدراتها في مجال حل المشاكل. يقول طالب الدكتوراة في مختبر ماكس تاغمارك في إم آي تي وعضو الفريق البحثي، زيمينغ ليو: "لقد أعدنا إحياء هذه الفكرة. ونأمل أنه مع إمكانية التفسير، ربما لن نضطر بعد الآن إلى الاعتقاد بأن الشبكات العصبونية تمثل صناديق سوداء".
على الرغم من أن العمل ما زال في مراحله الأولى، فإن عمل الفريق على شبكات "كان" يلفت الانتباه. فقد ظهرت بعض الصفحات على منصة غيت هاب (GitHub) لتوضيح كيفية استخدام شبكات "كان" في عدد كبير من التطبيقات، مثل التعرف على الصور وحل مسائل ديناميكا الموائع.
العثور على المعادلة
نجم التطور الحالي عن سعي ليو وزملائه في إم آي تي ومعهد كاليفورنيا للتكنولوجيا (كالتك) وغير ذلك من المعاهد إلى فهم العمليات الداخلية للشبكات العصبونية المعيارية التقليدية.
حالياً، تتضمن أنواع أنظمة الذكاء الاصطناعي كلها تقريباً، بما فيها الأنظمة المستخدَمة في بناء النماذج اللغوية الكبيرة وأنظمة التعرف على الصور، شبكات فرعية معروفة باسم "المستقبِلات المتعددة الطبقات" (multilayer perceptron)، أو اختصاراً "إم إل بي" (MLP). وفي هذه المستقبلات المتعددة الطبقات، تتوزع العصبونات الاصطناعية ضمن "طبقات" كثيفة ومترابطة. يحمل كل عصبون في داخله شيئاً نسميه "تابع التفعيل" (activation function)، وهو عملية رياضية تستقبل مجموعة من المدخلات (inputs) وتحولها بطريقة محددة مسبقاً إلى مُخرَج (output).
في المستقبِل المتعدد الطبقات، يتلقى كل عصبون اصطناعي مدخلات من العصبونات الموجودة في الطبقة السابقة كلها، ويجري عملية جداء لكل واحد من هذه المدخلات مع "وزن" أو "عامل تثقيل" (weight) موافق له، وهو رقم يرمز إلى أهمية هذا المُدخَل. يجري جمع هذه المدخلات الموزونة معاً وتلقيمها إلى تابع التفعيل داخل العصبون لتوليد المخرج، الذي يجري تمريره بدوره إلى العصبونات في الطبقة التالية. يتعلم المستقبل المتعدد الطبقات كيفية التمييز بين صور القطط والكلاب، على سبيل المثال، من خلال اختيار القيم الصحيحة لأوزان المدخلات من أجل العصبونات كلها. أما الأهم من هذا فهو أن تابع التفعيل ثابت ولا يتغير خلال التدريب.
بعد انتهاء التدريب، تتصرف العصبونات في المستقبل المتعدد الطبقات كلها، إلى جانب وصلاتها من حيث المبدأ، كأنها تابع آخر يتلقى مُدخلاً معيناً (لنفترض أنه عشرات الآلاف من البيكسلات في صورة على سبيل المثال) وينتج المخرج المطلوب (لنفترض أنه 0 للدلالة على القط و1 للدلالة على الكلب، على سبيل المثال). إن فهم طبيعة هذا التابع، أي صيغته الرياضية، جزء مهم من القدرة على فهم آلية إنتاجه لهذا المُخرج أو ذاك. على سبيل المثال، لماذا يصنف شخصاً ما على أنه يتمتع بالجدارة الائتمانية، بالنظر إلى المعلومات المتوفرة حول وضعه المادي؟ غير أن المستقبلات المتعددة الطبقات صناديق سوداء بالفعل. تطبيق الهندسة العكسية على الشبكة يكاد يكون مستحيلاً بالنسبة إلى المهام المعقدة، مثل التعرف على الصور.
وحتى عندما حاول ليو وزملاؤه تطبيق الهندسة العكسية على مستقبل متعدد الطبقات مخصص لمهام أبسط تعتمد على بيانات "اصطناعية" مصممة خصيصاً لهذا الغرض، فقد واجهوا صعوبات.
يقول ليو: "إذا لم نتمكن حتى من تفسير تلك المجموعات من البيانات الاصطناعية الناتجة عن الشبكات العصبونية، فإن التعامل مع مجموعات البيانات المشتقة من العالم الحقيقي أمر مستحيل وميؤوس منه. لقد واجهنا صعوبات بالغة لدى محاولتنا فهم هذه الشبكات العصبونية. ولهذا، أردنا أن نغير بنيتها".
تحديد معالم الصيغة الرياضية
اعتمد التغيير الرئيسي على فكرة إزالة تابع التفعيل الثابت، والاستعاضة عنه بتابع أبسط بكثير وقابل للتعلم، وذلك لتحويل كل مُدخل وارد قبل دخوله إلى العصبون.
وعلى عكس تابع التفعيل في عصبون المستقبل المتعدد الطبقات، الذي يستقبل عدة مدخلات، فإن كل تابع بسيط خارج عصبون "كان" يستقبل رقماً واحداً وينتج رقماً آخرَ (عند مخرجه). خلال التدريب، لا تتعلم شبكة "كان" الأوزان الفردية، كما يحدث في المستقبل المتعدد الطبقات، بل تتعلم بدلاً من ذلك كيفية تمثيل كل تابع بسيط وحسب. في ورقة بحثية نشرها ليو وزملاؤه هذا العام على خادم أركايف (ArXiv) للأبحاث التي ما زالت في مرحلة ما قبل النشر، أظهر الباحثون أن تفسير هذه التوابع البسيطة خارج العصبونات أسهل بكثير، ما يجعل من الممكن إعادة بناء الصيغة الرياضية للتابع الذي تتعلمه شبكة "كان" بالكامل.
ومع ذلك، لم يختبر الفريق قابلية تفسير شبكات "كان" إلا على مجموعات بيانات بسيطة واصطناعية فقط، لا على مسائل من العالم الحقيقي، مثل التعرف على الصور، والتي هي أعقد بكثير. فقد تكون القدرة على التفسير مهمة عسيرة للغاية".
وقد أظهر ليو وزملاؤه أيضاً أن شبكات "كان" تصبح أدق في تنفيذ مهامها مع زيادة حجمها، بوتيرة أسرع مما تفعل المستقبلات المتعددة الطبقات. أثبت الفريق هذه النتيجة نظرياً، وأظهرها تجريبياً بالنسبة إلى المهام ذات الطابع العلمي، مثل تعلم تقريب التوابع المتعلقة بالمسائل الفيزيائية. يقول ليو: "ما زال من غير الواضح بالنسبة لنا إن كانت هذه الملاحظة ستنطبق أيضاً على مهام التعلم العميق المعيارية، لكن الوضع يبدو واعداً بالنسبة إلى المهام المتعلقة بالعلوم على الأقل".
يعترف ليو بأن شبكات "كان" تتسم بصفة سلبية بارزة واحدة، وهي أن تدريبها يتطلب وقتاً أطول وإمكانات حاسوبية أعلى مقارنة بالمستقبل المتعدد الطبقات.
يقول الباحث في جامعة شيان جياوتونغ-ليفربول بمدينة سوجو في الصين، دي جانغ: "هذا يحدُّ من كفاءة تطبيق شبكات كان على مجموعات البيانات الضخمة والمهام المعقدة". لكنه يشير إلى أنه من الممكن التعامل مع هذه المشكلة من خلال الاعتماد على خوارزميات أكثر فاعلية وأنظمة خاصة لتسريع عمل المكونات المادية.