
في اليوم العالمي للغة العربية الذي يصادف يوم 18 ديسمبر من كل عام، لا بدّ من وقفة تأمل للعلاقة التي تربط بين لغتنا ولغة العصر: الذكاء الاصطناعي.
مَن بيننا لم يتساءل: لِمَ لا أستطيع مخاطبة معظم المساعدات الصوتية باللغة العربية؟ لِمَ لا يمكنني إجراء محادثة مع سيري باللهجة الخليجية أو المصرية؟ لماذا لا تستطيع أليكسا أن تفهم وتنفذ أوامري الصوتية باللهجة الشامية أو المغاربية؟ عندما أستخدم ترجمة جوجل، لماذا تترجم اختصار الذكاء الاصطناعي (AI) من الإنجليزية إلى العربية: (منظمة العفو الدولية)؟ لماذا -ضمن مجموعة واسعة من برامج تحويل الكلام إلى نص مكتوب- ليس هناك إلا حفنة منها تدعم اللغة العربية؟ لماذا يصر المصحح التلقائي للكتابة في الهاتف على أن الكلمة العامية التي أكتبها خاطئة، ويقترح عليّ بدائل فُصحى؟
بالطبع، جميع هذه الأدوات تعتمد على تقنيات الذكاء الاصطناعي، الذي نسمع باستمرار عن قدراته “الخارقة”. فهل عَجِزَ البطل أمام “مطبات” اللغة العربية وأحجم عن تجاوزها؟ هل عجز التعلم العميق عن الغوص عميقاً في كنوز لغتنا والخروج بقصة خيالية متماسكة كما نجح في الإنجليزية؟ هل ارتبكت معالجة اللغات الطبيعية وصَعُب عليها هضم قصائد الشعر العربي والإتيان ببيت على شاكلة شعر المتنبي أو نزار قباني، مع أنها قامت بأمر مماثل مع أشعار روبرت فروست؟
لماذا يعاني الذكاء الاصطناعي في توطيد علاقته بلغة الضاد التي يتحدثها حوالي 450 مليون شخص؟
لعلَّ الخلل في اللغة العربية؟! أم ربما سوء تفاهم بينها وبين التكنولوجيا؟
للإجابة عن هذه الأسئلة، نستعرض فيما يلي أبرز التحديات التي يواجهها الباحثون في تطوير أنظمة ذكاء اصطناعي قادرة على معالجة اللغة العربية وفهم اللهجات المحلية. كما نتناول أهم الجهود المبذولة لتذليل هذه العقبات.
أهم تحديات الذكاء الاصطناعي عند معالجة اللغة العربية
يواجه دعم الذكاء الاصطناعي للغة العربية جملة من الصعوبات، إليكم أهمها:
1. الشحّ في موارد اللغة العربية
تعتمد أنظمة الذكاء الاصطناعي على توافر كميات كبيرة من البيانات لتدريب النماذج اللغوية سواء كانت الغاية ترجمة النص أو التعرف على اللهجة التي كُتب بها أو تحديد الكلمات ونوعها (فعل أو اسم أو غيرهما) أو تحويل الكلام إلى نص مكتوب. وفي مجال معالجة اللغات الطبيعية تسمى هذه البيانات موارد أو مكانز لغوية. وفي الترجمة الآلية على سبيل المثال، كلما كان حجم البيانات أكبر، استطاعت الحواسيب أن تحدد على نحو أكثر دقةَ المصطلح العربي الأكثر استخداماً باعتباره الترجمة الصحيحة لمصطلح في لغة أخرى.
وفي حين يتوافر كمٌّ هائل من الموارد في اللغة الإنجليزية، تعد اللغة العربية من اللغات الفقيرة نسبياً بالموارد الموسومة الضرورية في تدريب نماذج الذكاء الاصطناعي. وتمثل هذه المسألة أحد التحديات التي تواجه باحثي اللسانيات الحاسوبية العاملين في معالجة اللغة العربية. حيث يضطر هؤلاء في معظم الأحيان إلى بناء مواردهم الخاصة ووسمها، مع ما يتطلبه ذلك من وقت وجهد وتمويل.
ويقول الدكتور نزار حبش، أستاذ في برنامج علوم الحاسوب في جامعة نيويورك أبوظبي ومدير مختبر الأساليب الحاسوبية لنمذجة اللغة (مختبر كامل CAMeL)، إنه حتى عام 2018، كانت هناك أربعة موارد بيانات موسومة نحوياً للغة العربية، وجميعها تم تطويره خارج العالم العربي: اثنان في الولايات المتحدة، وواحد في المملكة المتحدة وواحد في جمهورية التشيك. هذه الموارد مهمة جدا للبحث العلمي ولتطوير تطبيقات الذكاء الاصطناعي اللغوي.
2. تعدد اللهجات العربية
هناك ثلاثة أشكال للغة العربية: فصحى التراث، المستخدمة في الوثائق والنصوص التاريخية، والفصحى المعاصرة، وهي اللغة الرسمية في الدول العربية والمستخدمة في الصحف ووسائل الإعلام، واللهجات العامية، المستخدمة في الشارع والأحاديث اليومية بين الناس.
ورغم أن الأخيرة لم تكن مكتوبة على نطاق واسع، إلا أن ظهور وسائل التواصل الاجتماعي جعل منها الشكل الأكثر استخداماً في التعبير عن مشاعر وأفكار الشعوب العربية؛ ما أبرز الحاجة إلى بناء موارد بيانات لهذه اللهجات ومعالجتها آلياً سواء لتحليل مشاعر الجمهور أو تحديد مدى رضا العملاء أو اكتشاف مواقف المواطنين من السياسات الحكومية أو الاعتماد على بوتات دردشة تستطيع مخاطبة المستخدم بلهجته المحلية، وغيرها من الاستخدامات.
لكن المشكلة تكمن في أن هذه اللهجات تختلف في كتابتها و”قواعدها” عن اللغة العربية الفصحى، بالتالي فإن نماذج التعلم الآلي التي جرى تدريبها على موارد اللغة الفصحى ستفشل تماماً في التعامل مع النصوص المكتوبة باللهجة العامية والتعرف على كلماتها. أضف إلى ذلك التنوع الكبير في اللهجات من المغاربية إلى الخليجية إلى المصرية والشامية والعراقية، بل حتى أن هناك تبايناً في اللهجات بين سكان البلد الواحد. وكل ذلك يزيد من صعوبة تطوير نماذج ذكاء اصطناعي تستطيع التعرف على كل لهجة منها والتهجئات المختلفة لنفس الكلمة.
3. الإبهام الإملائي والثراء الصرفي
تتسم اللغة العربية بالغموض الإملائي؛ إذ يمكن للجذر اللغوي الواحد توليد العديد من الكلمات ذات المعاني المختلفة. كما يختلف شكل الحرف نفسه حسب موقعه داخل الكلمة. كما أن الحروف العربية لا تحتوي على أحرف كبيرة أو صغيرة، ما يجعل تحديد أسماء العلم أو الكيانات أمراً صعباً.
عَلَاوَةً عَلَى ذلِكَ، هُنَاكَ مَسْأَلَةُ التَّشْكِيل؛ إِذْ تُغيّرُ عَلَامَاتُ التَّشْكيل النُّطْقَ والصِّيغَةَ النَّحْوِيّة وحَتَّى مَعْنَى الكَلِمَاتِ فِي بَعْضِ الأَحْيَان. وَفي المُقابل، يُؤدِّي افتِقارُ الكَلِمَةِ إِلَى التَّشْكِيل -وَنَادِراً مَا يَتمُّ تَشْكِيلُ الكَلِمَاتِ حَتَّى فِي الصُّحُفِ الرَّسْميَّة- إِلى زِيَادةِ الِالْتِباسِ الدِّلَالِيّ. وَلَو عَلِمْنا أنَّ كُلَّ حَرفٍ مِن حُروفِ اللُّغَةِ العَرَبيَّة يَحْتَمِل فِي المُتَوسِّط 7 عَلامَاتِ تَشْكيلٍ مُمْكِنَة، يَتَّضِحُ مَدَى صُعُوبَةِ وَسْمِ الكَلِمَاتِ وَتَدْريبِ خَوارِزْمِيَّاتِ الذَّكَاءِ الاِصْطِنَاعِيّ عَلَى فَكّ غُمُوضِهَا واسْتِيعَابِ مَعَانِيهَا، وتَتَّضِحُ أَيْضاً أَهَمِّيَّةُ بِنَاءِ أَنْظِمَةِ تَشْكِيلٍ لِلُّغَةِ العَرَبِيَّة فِي تَصْمِيمِ تَطْبِيقَاتِ مُعَالَجَتِها.
وفي ندوة افتراضية أقامتها هارفارد بزنس ريفيو مؤخراً بعنوان “الذكاء الاصطناعي واللغة العربية: تحديات وحلول“، قال الدكتور حبش إن اللغة العربية تمتلك نظاماً صرفياً غنياً ينتج تراكيب صرفية كثيرة. وعلى سبيل المثال، كلمة “وسنقولها” تمثل واحداً من مئات التصريف الممكنة للفعل “قال”.

وفي حين يعتقد المرء أن اللهجات العامية تخلو من هذا التعقيد الصرفي، يشير الدكتور حبش إلى أنها قد تكون أكثر صعوبة من الفصحى في بعض الأحيان، ويورد مثالاً على عبارة “لا يقولها” باللهجة المصرية.

ووفقاً لما قالته كندا الطربوش، الرئيسة التنفيذية في محرك البحث لبلب، لإم آي تي تكنولوجي ريفيو العربية، فإن الغنى الصرفي للغة العربية يمثل أهم التحديات التي تواجه محركات البحث الحالية؛ حيث إن أغلب الأدوات الحالية المستخدمة في معالجة التصريف لا تلبي تطلعات تطوير محركات بحث ذكية قادرة على تمييز الكلمات العربية المتقاربة في الشكل والمختلفة في المعنى. وأوردت مثالاً حين يقوم المستخدم بكتابة استعلام بطريقة خاطئة ومستعجلة، كأن يكتب “دفع الإلكترون” عوضاً عن “الدفع الإلكتروني”؛ حيث إن كلمتي “الإلكترون” و”الإلكتروني” مختلفتان من حيث المعنى، ما يؤدي إلى حصول المستخدم على نتائج بحث خاطئة.
4. محدودية البحث العلمي في مجال معالجة اللغة العربية
من نافل القول أن البحث العلمي في الدول العربية بشكل عام لا يحظى بالدعم والتشجيع الذي يستحقه، ومجال الذكاء الاصطناعي ليس استثناءً. فعلى الرغم من وجود عدد كبير من الباحثين العرب في علوم الحاسوب واللسانيات واللغة، فإنهم لا يحصلون على ما يكفي من التمويل الحكومي أو الخاص لإجراء أبحاثهم.
علاوة على ذلك، فإن عقلية المصادر المفتوحة غائبة في منطقتنا عموماً؛ حيث تحتكر الشركات أبحاثها العلمية وأدواتها ومواردها خوفاً من المنافسة. وكذلك الحال في التعاون البحثي بين الجامعات ومراكز الأبحاث، ما يرغم الباحثين في مجال معالجة اللغة العربية على بناء مواردهم الخاصة وتطوير خوارزمياتهم من نقطة الصفر.
قد يهمك أيضاً:
أبرز حلول الذكاء الاصطناعي في معالجة اللغة العربية
إن هذه التحديات آنفة الذكر تجعل من اللغة العربية حالة فريدة من نوعها بالنسبة لتقنيات الذكاء الاصطناعي، وتفرض على المتخصصين بذل جهود مكثفة على عدة مستويات لتمكين هذه التقنيات من التعامل معها واستيعابها. نستعرض فيما يلي جانباً من هذه الجهود التي لا يتسع المجال هنا لذكرها كلها، لذا نورد بعض الأمثلة.
قام الدكتور حبش وفريقه من الباحثين في جامعة نيويورك أبوظبي بتطوير نظام قائم على الذكاء الاصطناعي يستطيع التعرف تلقائياً على العربية الفصحى واللهجات المختلفة في 25 مدينة عربية. ويقوم النظام المسمى عديدة (ADIDA) بالتعرف على النص الذي يدخله المستخدم ثم يظهر خريطة جغرافية للوطن العربي تبيِّن المدن التي تستخدم هذا النص، ثم يعرض المدن الخمسة الأولى التي يحتمل أن يستخدم سكانها هذه الطريقة في الكلام والكتابة (يمكنك تجربة نظام ADIDA هنا).
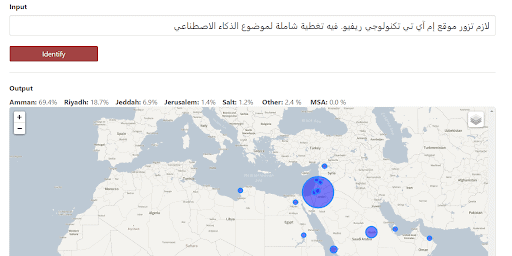
وقد اعتمد فريق الدكتور نزار حبش على مورد بيانات يضم 100 ألف جملة (ملف بي دي إف) مترجمة من الإنجليزية أو الفرنسية إلى لهجات المدن الـ 25، ويحتوي كذلك على 12 ألف جملة بالعربية الفصحى، ويبلغ عدد الكلمات المستخدمة في كل الجمل نحو 800 ألف كلمة، كما تم بناء قاموس متعدد اللهجات يحتوي على 47 ألف مفردة.
كما قام الدكتور حبش وفريقه في مختبر كامل بإنشاء مكنز قُمَر (Gumar) للهجة العربية الخليجية، الذي يضم أكثر من 100 مليون كلمة من روايات باللهجة الخليجية، وتطوير المحلل الصرفي الإملائي مداميرا (MADAMIRA) بالاعتماد على التعلم العميق.
ومن الجهود الجديرة بالذكر في هذا الصدد، نشير إلى مدونة اللهجة العامية الفلسطينية كُرّاس (Curras)، التي طورها الدكتور مصطفى جرّار وزملاؤه من جامعة بيرزيت بالتعاون مع جامعة نيويورك أبوظبي. وتتيح المدونة معالجة وتحديد وتصنيف وترجمة أكثر من 55 ألف كلمة باللهجة الفلسطينية (ملف بي دي إف) إلى اللغة العربية الفصحى واللغة الإنجليزية. وقد فازت هذه المدونة بجائزة البحث في مجال معالجة اللغات الطبيعية من شركة جوجل (يمكنك الاطلاع على مدونة كُرّاس هنا).
كما يعتمد محرك البحث لبلب على تقنيات الذكاء الاصطناعي لتحسين فهم اللغة العربية. ويستخدم أنظمة قائمة على التعلم الآلي، مثل نظام المترادفات والاقتراحات، والإكمال التلقائي، والمصحِّح الإملائي، وترتيب نتائج البحث؛ لتقديم نتائج بحث أعلى جودة لمستخدمي اللغة العربية. وقد أوضحت كندا الطربوش أن الباحثين في لبلب يعملون على تطوير معالجة اللهجات العربية لتوفير إمكانية البحث باستخدام اللهجات. وقالت: “يعمل لبلب على محورين اثنين في هذا المجال: توفير بيانات ضخمة للهجات العربية، واستخدام نماذج التعلم العميق لتوفير بحث قادر على فهم اللهجات العربية”. وأوضحت الطربوش أنه وفقاً لإحصائيات مستخدمي لبلب، فإن ما نسبته 30% من استعلامات البحث تتم باستخدام اللهجات المحلية؛ لذا -وللتغلب على هذا التحدي- يعقد لبلب شراكات مع جامعات عربية ومخابر مختصة في مجال اللغة العربية لتطوير الأبحاث حول معالجة اللهجات العربية.
ومن الأمثلة على تطبيقات الذكاء الاصطناعي في اللغة العربية، نذكر بوت الدردشة من شركة أرابوت (AraBot) التي أسسها رائد الأعمال الأردني عبدالله فزع وشريكه. وبالاعتماد على تقنيات معالجة اللغات الطبيعية، يستطيع البوت إجراء محادثة باللغتين العربية والإنجليزية بالإضافة إلى اللهجات العربية المختلفة. كما أطلقت منصة موضوع، ومقرها عمَّان، المساعدة الصوتية سلمى في عام 2019، التي تعتمد على الذكاء الاصطناعي للدردشة الصوتية باللغة العربية وتمثل بديلاً عربياً للمساعدات الأخرى مثل أليكسا وسيري. وهناك العديد من بوتات الدردشة العربية الأخرى التي تم تطويرها خلال السنوات الأخيرة مثل: بوت نبيهة (Nabiha) الخاص باللهجة السعودية وبوتا (BOTTA) الخاص باللهجة المصرية.
قام باحثون من الجامعة الأميركية في بيروت أيضاً بتطوير نموذج الذكاء الاصطناعي أرابيرت (AraBERT) القائم على النموذج اللغوي الشهير بيرت من جوجل. وقد حقق النموذج نتائج ممتازة في مهام مثل تحليل المشاعر وتحديد أسماء الكيانات والإجابة عن الأسئلة باللغة العربية.
وكمثال على مساهمة الشركات التكنولوجية الكبرى في هذا الصدد، نذكر إعلان جوجل في عام 2019 عن إضافة اللغة العربية واللهجتين السعودية والمصرية إلى مساعدها الذكي (Google Assistant)، متيحةً بذلك للمستخدمين إمكانية مخاطبة المساعد الصوتي بلهجتهم المحلية للتعرف على حالات الطقس والرد على المكالمات بالأوامر الصوتية، والتأكد من مواعيد الصلاة وقراءة البريد الإلكتروني وغيرها من الخدمات باستخدام اللغة العربية.
أما على مستوى العمل الحكومي، وضمن إطار القمة العالمية للذكاء الاصطناعي التي استضافتها المملكة العربية السعودية مؤخراً، أعلن المركز الوطني السعودي للذكاء الاصطناعي عن توقيع مذكرة تفاهم مع شركة هواوي تهدف إلى التعاون الإستراتيجي لتفعيل البرنامج الوطني لتنمية القدرات، إحدى مبادرات المملكة الرامية لتطوير إمكانات الذكاء الاصطناعي المحلية. وتضمنت مذكرة التفاهم أيضاً برامج تدريب المهندسين والطلاب السعوديين المتخصصين في مجال الذكاء الاصطناعي، فضلاً عن التطوير المشترك لرفع إمكانيات الذكاء الاصطناعي الخاصة باللغة العربية. كما تندرج المعالجة الطبيعية للغة العربية ضمن أولويات المجلس الوطني المصري للذكاء الاصطناعي الذي تم تأسيسه في عام 2019.
اقرأ أيضاً: هل الذكاء الاصطناعي يهدد البشرية؟
مستقبل الذكاء الاصطناعي في معالجة اللغة العربية
على الرغم من التحديات والصعوبات التي تواجه تطوير تقنيات الذكاء الاصطناعي لمعالجة اللغة العربية، إلا أن هناك عاملان رئيسان يدعوان إلى التفاؤل بتحقيق اختراقات كبرى في هذا المضمار: الأول هو جهود الباحثين -العرب والأجانب- من أمثال الدكتور حبش وفريق لبلب، التي نجحت خلال فترة قصيرة نسبياً أن تحرز تقدماً كبيراً على أكثر من صعيد. والآخر هو الإمكانات الاقتصادية والاجتماعية والسياسية الواعدة لتطوير معالجة اللغة العربية والاستفادة من ذلك في “تطبيقات لا حدود لها” على حد وصف كندا الطربوش، مثل اكتشاف توجهات الشعوب العربية وتطلعاتها، وتحقيق تواصل أفضل بين الحكومات والمواطنين، وخدمة العملاء والاستماع لآرائهم بلهجاتهم وتحسين تجربتهم، وتجويد تعليم اللغة العربية وتكييفه، وتنظيم المحتوى العربي على الإنترنت، وتطوير مساعدات صوتية عربية ذات جودة عالية، وغير ذلك مما من شأنه أن يشجع الشركات والحكومات على توفير المزيد من الدعم والتمويل لهذه الغاية.
في العام الماضي احتفت اليونسكو باليوم العالمي للغة العربية تحت شعار “اللغة العربية والذكاء الاصطناعي”، وناقشت كيفية تحويل الذكاء الاصطناعي إلى وسيلة لتيسير الحوار بين الشعوب والثقافات وأداة لتعزيز اللغة العربية وصونها. وفي الأعوام القليلة القادمة، نأمل أن يتوافر دعم أكبر وأن نشهد نجاحات أكبر لتقنيات الذكاء الاصطناعي في معالجة اللغة العربية والتعامل مع مشكلات التحيز الجنسي في الترجمة الآلية وغيرها من التحديات، وأن يتحول الذكاء الاصطناعي حقاً إلى الغوّاص الذي ذكره الشاعر حافظ إبراهيم في البيت الشعري الشهير:
أَنا البَحرُ في أَحشائِهِ الدُرُّ كامِنٌ فَهَل سَاءَلوا الغَوّاصَ عَن صَدَفاتي
اقرأ أيضا: