
هل يجب على الشركات أن تتحمل مسؤوليات اجتماعية؟ أم أن الهدف من وجودها هو تحقيق الربح لحملة أسهمها وحسب؟ إذا وجهت هذا السؤال إلى نظام ذكاء اصطناعي، فقد تحصل على إجابات متباينة للغاية، اعتماداً على النموذج الذي تسأله. وعلى حين تؤيد النماذج الأقدم من أوبن أيه آي (OpenAI)، جي بي تي 2 (GPT-2) وجي بي تي 3 آدا (GPT-3 Ada)، العبارة الأولى، فإن جي بي تي 3 دافينشي (GPT-3 Da Vinci) الذي يتميز بقدرات أعلى، سيتفق مع العبارة الثانية.
تحيزات سياسية في النماذج اللغوية
يُعزى هذا إلى احتواء نماذج الذكاء الاصطناعي اللغوية على تحيزات سياسية مختلفة، وذلك وفقاً لبحث جديد من جامعة واشنطن، وجامعة كارنيغي ميلون، وجامعة شيان جياوتونغ. أجرى الباحثون اختبارات على 14 نموذجاً لغوياً كبيراً، ووجدوا أن تشات جي بي تي (ChatGPT) وجي بي تي 4 (GPT-4) من أوبن أيه آي هما الأكثر ميلاً نحو اليسار المتحرر، على حين وجدوا أن لاما (LLaMa) من ميتا (Meta) كان الأكثر ميلاً نحو اليمين المتسلط.
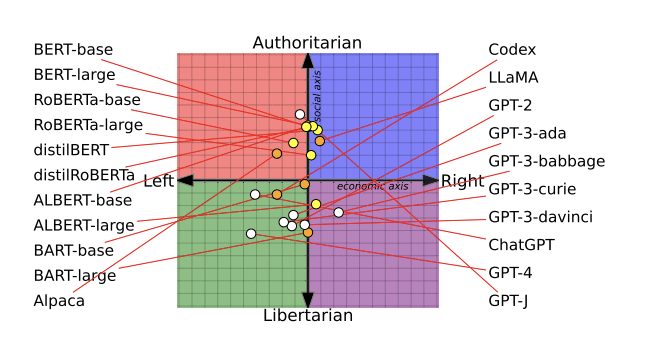
سأل الباحثون النماذج اللغوية حول مواقفها إزاء عدة مواضيع، مثل الحركة النسوية والديمقراطية. واستخدموا الإجابات التي حصلوا عليها لتحديد مواضع هذه النماذج ضمن مخطط بياني يُعرف باسم البوصلة السياسية، وبعد ذلك، اختبروا ما إذا كانت إعادة تدريب النماذج باستخدام بيانات تدريب أكثر تحيزاً سياسياً حتى ستؤدي إلى تغيير سلوكها وقدرتها على كشف خطاب الكراهية والمعلومات المزيفة (وقد تَحقق هذا فعلاً). قُدم البحث في ورقة بحثية خضعت لمراجعة الأقران وفازت بجائزة أفضل ورقة بحثية في مؤتمر اتحاد علم اللسانيات الحاسوبية الذي عُقِد في يوليو المنصرم.
مع إطلاق النماذج اللغوية التي تعتمد على الذكاء الاصطناعي في منتجات وخدمات يستخدمها الملايين من الناس، يتسم إدراك افتراضاتها وتحيزاتها السياسية الكامنة بأهمية فائقة. وذلك لقدرتها على إحداث أضرار حقيقية. فقد يرفض بوت الدردشة الذي يقدم نصائح تخص العناية الصحية تقديم نصيحة حول الإجهاض أو وسائل منع الحمل، وقد يبدأ بوت يتولى خدمة العملاء بإطلاق عبارات مسيئة لا تحمل معنى واضحاً.
منذ نجاح تشات جي بي تي، تعرضت أوبن أيه آي إلى انتقادات حادة من المعلّقين اليمينيين الذين يزعمون أن بوت الدردشة يعكس وجهة نظر أكثر تحرراً تجاه العالم. لكن الشركة تصر على أنها تعمل على مواجهة هذه المخاوف، وقد قالت في منشور مدونة إنها أعطت تعليماتها لمراجعيها من البشر، الذين يساعدون على الضبط الدقيق لنموذج الذكاء الاصطناعي، بعدم تفضيل أي مجموعة سياسية. يقول المنشور: "إن التحيزات التي قد تنتج على أي حال من العملية الموصوفة أعلاه أخطاء برمجية، وليست ميزات للبرنامج".
لكن باحثة الدكتوراة في جامعة كارنيغي ميلون، تشان بارك، التي كانت أحد أعضاء فريق الدراسة، لا توافق على هذه الفكرة. وتقول: "نعتقد أنه ليس من الممكن لنموذج لغوي أن يخلو تماماً من التحيزات السياسية".
اقرأ أيضاً: أوبن أيه آي: «جي بي تي-4» تمكن من تخطي اختبار «كابتشا»
تتسرب التحيزات إلى النماذج في جميع مراحل بنائها
لاستنباط كيفية التقاط النماذج اللغوية التي تعمل بالذكاء الاصطناعي للتحيزات السياسية بتطبيق الهندسة العكسية، درس الباحثون ثلاث مراحل من عملية تطوير النموذج.
في الخطوة الأولى، طلبوا من 14 نموذجاً لغوياً التعبير عن تأييد أو مخالفة مجموعة من العبارات التي تحمل طابعاً سياسياً واضحاً، والتي بلغ عددها 62 عبارة. وهو ما ساعدهم على تحديد الميول السياسية الكامنة للنماذج وتحديد موضعها على البوصلة السياسية. وقد تفاجأ الفريق بوجود توجهات سياسية متباينة على نحو واضح لنماذج الذكاء الاصطناعي، وفقاً لبارك.
ووجد الباحثون أن نماذج بيرت (BERT)، وهي نماذج ذكاء اصطناعي لغوية طورتها جوجل، كانت أقرب إلى التوجه المحافظ اجتماعياً من نماذج جي بي تي من أوبن أيه آي. وعلى عكس نماذج جي بي تي، التي تتنبأ بالكلمة التي سترد تالياً في الجملة، تتنبأ نماذج بيرت بأجزاء من الجملة باستخدام المعلومات المحيطة بها ضمن كتلة نصية. قد يُعزى التوجه المحافظ اجتماعياً لنماذج بيرت الأقدم إلى أنها دُرِّبَت باستخدام الكتب التي كانت تميل إلى الاتجاه المحافظ، على حين دُرِّبت نماذج جي بي تي الأحدث باستخدام نصوص منتشرة عبر الإنترنت تحمل ميولاً متحررة بدرجة أعلى، كما توقع الباحثون في ورقتهم البحثية.
أيضاً، يمكن لنماذج الذكاء الاصطناعي أن تتغير بمرور الوقت، مع تحديث الشركات التكنولوجية لمجموعات البيانات وطرق التدريب التي تخصها. على سبيل المثال، عبّر جي بي تي 2 عن تأييده لفكرة "فرض الضرائب على الأثرياء"، على حين عارض جي بي تي 3 الأحدث من أوبن أيه آي هذه الفكرة.
لم ترد جوجل وميتا على طلب إم آي تي تكنولوجي ريفيو منهما التعليق على معلومات المقال قبل النشر.
تضمنت الخطوة التالية إجراء تدريبات إضافية لنموذجي ذكاء اصطناعي لغويين، وهما جي بي تي 2 من أوبن أيه آي وروبيرتا (RoBERTa) من ميتا، باستخدام مجموعات بيانات تتألف من بيانات وسائل إعلامية إخبارية ووسائل تواصل اجتماعية جديدة من مصدرين يتمتعان بميول يمينية ويسارية، وفقاً لبارك. وقد أراد الفريق التأكد مما إذا كانت بيانات التدريب تؤثر على التحيزات السياسية.
وقد تبين أن هذا صحيح. وجد الفريق أن هذه العملية ساعدت على تقوية تحيزات النماذج، فالنماذج التي تميل إلى اليسار أصبحت أكثر ميلاً إلى اليسار، والنماذج التي تميل إلى اليمين أصبحت أكثر ميلاً إلى اليمين.
في المرحلة الثالثة من هذا البحث، وجد الفريق اختلافات كبيرة في كيفية تأثير الميول السياسية لنماذج الذكاء الاصطناعي على أنواع المحتوى التي صنفتها النماذج ضمن فئة خطاب الكراهية والمعلومات المزيفة.
فالنماذج المدربة ببيانات يسارية الميول كانت أكثر حساسية تجاه خطاب الكراهية الذي يستهدف الأقليات العرقية والدينية وغيرها من الأقليات في الولايات المتحدة، مثل أصحاب البشرة الداكنة وغيرهم من أفراد الأقليات الأخرى. أما النماذج المدربة ببيانات يمينية الميول كانت أكثر حساسية تجاه خطاب الكراهية الموجه ضد الرجال البيض.
أيضاً، كانت النماذج اللغوية ذات الميول اليسارية أفضل في كشف المعلومات المضللة من المصادر اليمينية، ولكنها كانت أقل حساسية إزاء المعلومات المضللة من المصادر اليمينية. أما النماذج اللغوية ذات الميول اليمينية فقد سلكت سلوكاً معاكساً.
اقرأ أيضاً: ما هو «جي بي تي-4»؟ ولماذا قد يمثل علامة فارقة في تاريخ الذكاء الاصطناعي؟
تنقية مجموعات البيانات من التحيز ليست كافية
وفي نهاية المطاف، لا يمكن للمراقبين الخارجيين تحديد سبب اختلاف التحيزات السياسية بين نماذج الذكاء الاصطناعي المختلفة، لأن الشركات التكنولوجية لا تشارك أي تفاصيل حول البيانات أو الطرائق المستخدمة في تدريبها، وفقاً لبارك.
جرب الباحثون طريقة للتخفيف من التحيزات الكامنة في النماذج اللغوية، وذلك بإزالة المحتوى المتحيز من مجموعات البيانات، أو فلترته. "السؤال المهم الذي تطرحه هذه الورقة البحثية هو التالي: هل تنقية البيانات [من التحيزات] كافية؟ الإجابة هي: كلا"، وفقاً للأستاذ المساعد المختص بعلوم الحاسوب في كلية دارتموث، سوروش فوسوغي، الذي لم يشارك في الدراسة.
من الصعب للغاية إزالة التحيزات على نحو تام من مجموعة بيانات ضخمة، وفقاً لفوسوغي، إضافة إلى ذلك، فإن نماذج الذكاء الاصطناعي تبدي قابلية كبيرة للتعبير حتى عن التحيزات الضعيفة التي قد تكون موجودة في البيانات.
من القيود التي تعرضت لها الدراسة عدم قدرة الباحثين على تطبيق المرحلة الثانية والثالثة إلا على نماذج صغيرة وقديمة نسبياً، مثل جي بي تي 2 وروبيرتا، وفقاً للعالم الباحث في شركة ديب مايند (DeepMind)، روبيو ليو، الذي درس التحيزات السياسية في نماذج الذكاء الاصطناعي اللغوية، ولكنه لم يشارك في البحث.
يقول ليو إنه يرغب في رؤية ما إذا كانت استنتاجات الورقة البحثية تنطبق على أحدث نماذج الذكاء الاصطناعي. لكن الباحثين الأكاديميين لا يستطيعون الاطلاع على الآليات الداخلية لأحدث أنظمة الذكاء الاصطناعي مثل تشات جي بي تي وجي بي تي 4، ومن المستبعد أن يتمكنوا من الاطلاع عليها، ما يزيد عملية التحليل صعوبة.
من القيود الأخرى للبحث ميل أنظمة الذكاء الاصطناعي إلى اختلاق المعلومات، ما يعني أن الإجابات التي يقدمها النموذج قد لا تعبر على نحو حقيقي عن "حالته الداخلية"، وفقاً لفوسوغي.
أيضاً، يعترف الباحثون أن اختبار البوصلة السياسية، وعلى الرغم من استخدامه على نطاق واسع، ليس بالطريقة المثالية لقياس تفاصيل السياسة ودقائقها.
اقرأ أيضاً: شركة أوبن أيه آي تواجه عواقب جشعها في جمع البيانات
مع دمج الشركات لنماذج الذكاء الاصطناعي في منتجاتها وخدماتها، يجب أن تكون أكثر إدراكاً لتأثير هذه التحيزات على سلوك نماذجها، كي تجعلها أكثر إنصافاً، حيث يقول بارك: "لا وجود للإنصاف من دون الوعي".