
ربما فاتتك مشاهدة طقوس الاحتفال ورذِّ قصاصات الورق الملون، حيث بدأ علماء اللغويات الحاسوبية يزعمون في الأشهر الأخيرة أن الترجمة الآلية العصبونية تضاهي الآن أداء المترجمين من البشر.
فقد تحسنت تقنية استخدام الشبكات العصبونية في ترجمة النصوص من لغة إلى أخرى بسرعة فائقة في السنوات الأخيرة، وذلك بفضل الإنجازات التي يتم تحقيقها بشكل متواصل في التعلم الآلي والذكاء الاصطناعي؛ وبالتالي ليس من المستبعد أن تكون الآلات قد اقتربت في أدائها من مضاهاة البشر، وفي الواقع فإن لدى علماء اللغويات الحاسوبية أدلة جيدة تدعم هذه المزاعم.
إلا أن سامويل لاوبلي (من جامعة زيورخ) واثنين من زملائه يرون ضرورة إيقاف هذه الاحتفالات، وهم هن لا ينقاشون نتائج زملائهم، ولكنهم يقولون فقط إن بروتوكول الاختبار لا يضع في الاعتبار الطريقة التي يقرأ بها البشر المستندات، وعندما يتم تقييم ذلك فسيتضح حينئذ التخلُّف الملحوظ للآلات مقارنة بالبشر، حسب تعبيرهم.
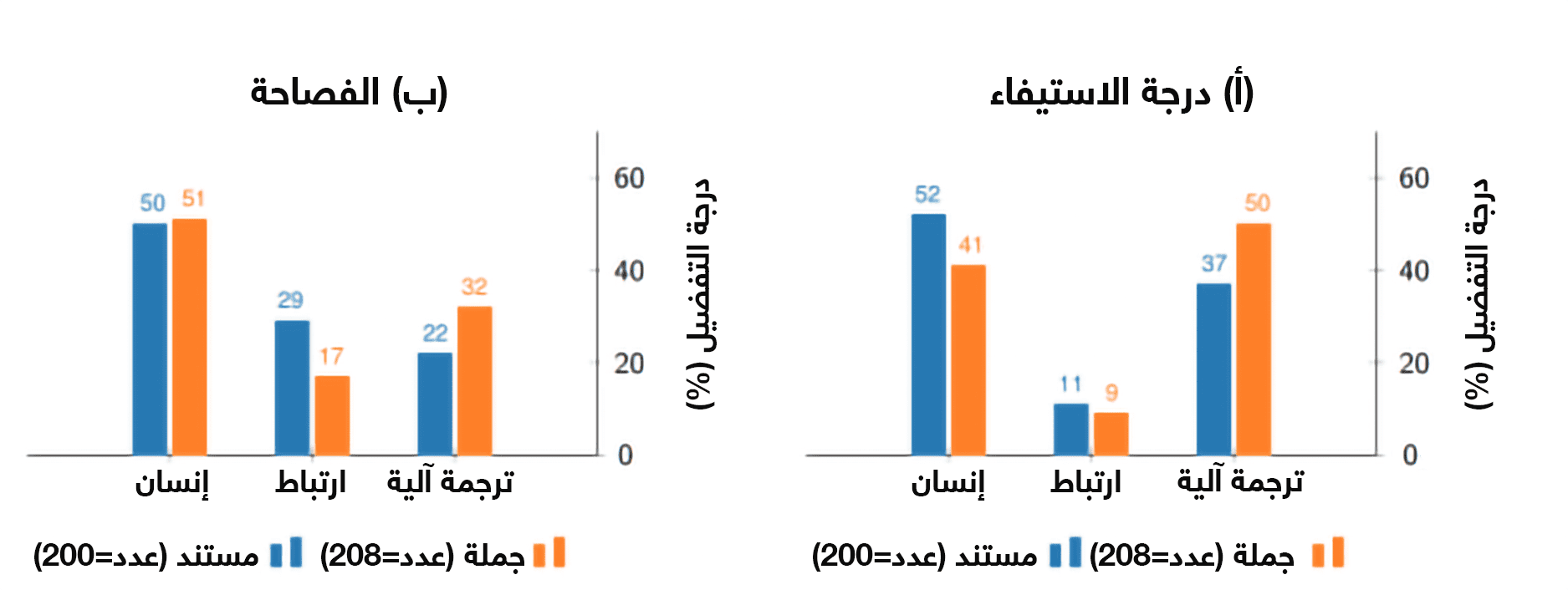
المسألة الجوهرية هي الكيفية التي ينبغي بها تقييم الترجمة الآلية، ويجري ذلك حالياً بالاعتماد على اثنين من المعايير، هما: درجة الاستيفاء، والفصاحة. ويتم تحديد درجة استيفاء الترجمة (أي: إيفاء الجملة الأصلية حقها من حيث المعنى) من قِبل مترجمين محترفين من البشر، حيث يقرؤون النص الأصلي ونص الترجمة المقابل لمعرفة مدى الجودة التي يُعبَّر بها عن معنى النص المصدري، أما الفصاحة فيتم الحكم عليها من قبل قُرَّاء لا يتحدثون سوى اللغة المترجم إليها، حيث يقرؤون نص الترجمة فقط، ويحدِّدون مدى الجودة التي كُتب بها في لغتهم.
ويتفق علماء اللغويات الحاسوبية على أن هذا النظام يقدِّم تقييمات مفيدة، إلا أن لاوبلي وزملائه يرون أن البروتوكول الحالي يقارن النصوص المترجمة على مستوى الجُمل، في حين يقوم البشر أيضاً بتقييم النص على مستوى المستند.
ولذلك قاموا بتطوير بروتوكول جديد لمقارنة الأداء بين الآلات والمترجمين البشر على مستوى المستند، حيث طلبوا من عددٍ من المترجمين المحترفين أن يقيِّموا مدى إجادة الآلات والبشر في ترجمة أكثر من 100 مقالة إخبارية مكتوب باللغة الصينية إلى الإنجليزية.
فقام مدققو الترجمة بتقييم كل نص من النصوص المترجمة من حيث درجة الاستيفاء والفصاحة على مستوى الجُمل، ولكن مع إيلاء أهمية بالغة للتقييم على مستوى المستند بأكمله.
وأسفرت التجربة عن نتائج جديرة بالاهتمام، فبدايةً لم يجد لاوبلي وزملاؤه فرقاً مهماً في الطريقة التي قيَّم بها المترجمون المحترفون درجة استيفاء الجمل التي تمَّت ترجمتها سواءً آلياً أو بشرياً، وقد تبيّن وفقاً لهذا المعيار أن كلاً من البشر والآلات يجيد الترجمة، وهو ما ينسجم مع النتائج السابقة.
ومع ذلك عندما يتعلق الأمر بتقييم المستند بالكامل، فإن نصوص الترجمة البشرية يتم تقييمها على أنها أكثر استيفاءً وفصاحة من نظيرتها الآلية، حيث يقول لاوبلي وزملاؤه: "إن البشر المسؤولين عن تقييم درجة الاستيفاء والفصاحة يُظهرون تفضيلهم بقوة للترجمة البشرية على الترجمة الآلية، وذلك عند تقييم المستندات مقارنة بتقييم الجمل بشكل منفرد".
ويعتقد الباحثون أنهم يعرفون السبب وراء ذلك، حيث يقولون: "نحن نفترض أن التقييم على مستوى المستند يكشف الستار عن أخطاء مثل إساءة الترجمة لإحدى الكلمات المبهمة، أو الأخطاء المتعلقة بالتماسك والاتساق على المستوى النصي، وهي أخطاءٌ يظل كشفها أثناء التقييم على مستوى الجمل أمراً صعباً، بل حتى مستحيلاً".
ويستشهد الفريق -على سبيل المثال- بتطبيق جديد يسمى "微信挪 车"، وهو اسم يترجمه البشر على الدوام إلى عبارة إنجليزية ثابتة، هي "WeChat Move the Car"، ولكن الآلات غالباً ما تترجمه بطرق مختلفة في نفس المقالة، حيث تترجمها إما إلى "Twitter Move Car"، أو "WeChat mobile"، أو "WeChat Move"، ويقول لاوبلي وزملاؤه إن هذا النوع من التضارب وعدم الاتساق يجعل من تتبُّع المستندات مهمةً أكثر صعوبة.
وهذا يشير إلى أن الطريقة التي يتم بها تقييم الترجمة الآلية في حاجة إلى التطوير، بعيداً عن الأنظمة التي تنظر فيها الآلات إلى الجمل وحدها، بمعزل عن بعضها البعض.
يقول لاوبلي وزملاؤه: "مع تحسُّن جودة الترجمة الآلية، سيغدو تمييز النصوص المترجمة أكثر صعوبة من حيث الجودة، ومن الممكن عندئذ أن يحين الوقت للانتقال إلى التقييم على مستوى المستند، مما يمنح المدققين مزيداً من السياق لفهم النص الأصلي وترجمته، ويكشف أيضاً أخطاء الترجمة المتعلقة بحالات الخطاب التي تبقى غير مرئية أثناء التقييم على مستوى الجملة".
وينبغي لمثل هذا الانتقال أن يساعد في تحسين الترجمة الآلية، وهذا يعني أنه لا يزال عليها أن تتجاوز مستوى الترجمة البشرية، وهو ما لم يتحقق حتى الآن.