
مع كل الضجة والإثارة التي ترافق الشبكات العصبونية وتقنيات التعلم العميق، من السهل أن ننسى أن عالم علوم الحاسوب يحوي مجالات وتقنيات أخرى أيضاً. وهو أمر متوقع، نظراً لأن الشبكات العصبونية بدأت تتفوق على البشر في مهام مثل التعرف على الأشياء والوجوه، وفي ألعاب مثل الشطرنج وجو، ومجموعة من ألعاب الفيديو.
صممت هذه الشبكات على أساس عمل الدماغ البشري، وبالتالي، لا يوجد ما يماثلها من إمكانية التطور والأداء، أليس كذلك؟
في الواقع، فهذا ليس صحيحاً تماماً. حيث يوجد أسلوب مختلف من الحوسبة يمكن أن يكون أكثر قوة من الشبكات العصبونية والتعلم العميق. وهذه التقنية مبنية على العملية التي أدت إلى نشوء الدماغ البشري: التطور، أي التتابع المتكرر من التغير والاختيار، والذي أدى إلى نشوء أعقد الآلات التي يعرفها البشر: العين، الجناح، الدماغ، وغير ذلك. إن قوة التطور عجائبية فعلاً.
ولهذا، حاول علماء الحاسوب منذ زمن استغلال إمكانيات التطور، وقد حققت ما تسمى بالحوسبة التطورية بعض الإنجازات الهامة على مدى 30 عاماً، منذ أن استخدمت لأول مرة في أمثَلَة عمل خطوط الإنتاج في معمل للجرارات. ولكن مؤخراً، تراجع هذا الحقل في علوم الحاسوب عن بقعة الضوء، تاركاً الواجهة لآلات التعلم العميق ونجاحها الباهر.
أما اليوم، فقد تنقلب الآية، وذلك بفضل عمل دينيس ويلسون وبضعة زملاء في جامعة تولوز في فرنسا. فقد أثبت هؤلاء الباحثون كيف يمكن للحوسبة التطورية أن تضاهي في الأداء آلات التعلم العميق في مهمة ذات أهمية رمزية أطلقتها إلى الشهرة في 2013، أي التفوق على البشر في ألعاب الفيديو، مثل بونج، بريك أوت، وسبيس إنفيدرز. ويقترح هذا العمل أن الحوسبة التطورية تستحق نفس الاهتمام الواسع الذي يحوز عليه أنسباؤها من خوارزميات التعلم العميق.
تعمل الحوسبة التطورية بأسلوب يختلف جذرياً عن عمل الشبكات العصبونية. والهدف هو تشكيل كود برمجي يحل مشكلة معينة باستخدام مقاربة تبدو نوعاً ما معاكسة للمنطق السليم. تقوم الطريقة التقليدية على كتابة الكود اعتماداً على مبادئ أساسية مع وجود هدف محدد، أما الحوسبة التطورية فتعتمد على أسلوب مختلف، حيث تبدأ مع كود مولد بطريقة عشوائية تماماً، بل مع عدة نسخ منه، تصل أحياناً إلى مئات الآلاف من مقاطع الكود البرمجي عشوائية التجميع.
يتم اختبار كل من هذه الكودات لمعرفة ما إذا كانت تحقق الهدف المطلوب، وبالطبع، تكون جميع النتائج سيئة نظراً للتجميع العشوائي للكود. ولكن يحدث بالصدفة أن بعض المقاطع أفضل من غيرها بقليل. ولهذا، يتم إعادة إنتاجها في عملية توليد برمجية جديدة، والتي تتضمن مزيداً من النسخ من مقاطع الكود الأفضل. ولكن الجيل التالي لا يمكن أن يكون نسخة مطابقة عن الجيل الأول، بل يجب أن يتغير بطريقة ما. وتتضمن هذه التغييرات المبادلة بين جزئين من الكود، بشكل أشبه بالتحول الجيني، أو يمكن أن تتم مبادلة نصفين من كودين مختلفين، بشكل يشبه التكاثر الجنسي. يتم بعد هذا اختبار كل كود من الجيل الجديد لمعرفة مدى صلاحيته للعمل. ومن ثم إعادة تشكيل أفضل الكودات في عملية توليد جديدة، وهكذا دواليك.
بهذه الطريقة، يتطور الكود. ومع مرور الوقت، يصبح أفضل، وبعد الكثير من الأجيال، بوجود الظروف الصحيحة، قد يصبح أفضل من أي كود يمكن للبشر تصميمه. وقد نجح علماء الحاسوب في تطبيق المقاربة التطورية على عدة مشاكل، بدءاً من تصميم الروبوتات وصولاً إلى بناء قطع الطائرات.
غير أن هذه الطريقة فقدت ألقها بسبب الاهتمام الكبير بالتعلم العميق. وبالتالي، فإن السؤال الذي يطرح نفسه هو قدرتها على مضاهاة أداء آلات التعلم العميق. وللعثور على الإجابة، قام ويلسون وزملاؤه باستخدام المقاربة لتطوير كود برمجي قادر على التحكم بألعاب الفيديو القديمة، التي تعود إلى فترة الثمانينيات والتسعينيات.
تتوافر هذه الألعاب في قاعدة بيانات تسمى ببيئة التعلم لألعاب الفيديو، وقد ازداد الاعتماد عليها لاختبار سلوك التعلم للخوارزميات من مختلف الأنواع. وتتألف قاعدة البيانات هذه من 61 لعبة من أتاري، مثل بونج، وسبيس إنفيدرز، وكونج فو ماستر.
تقوم المهمة على تشكيل خوارزمية قادرة على ممارسة لعبة مثل بونج فقط بالنظر إلى الخرج على الشاشة، كما يتعلمها البشر. وبالتالي، يجب على الخوارزمية أن تحلل كل موضع في اللعبة وتقرر كيف تتحرك للحصول على أعلى نتيجة ممكنة.
تشترك جميع الألعاب في نظام التحكم، والذي يتلخص في الاتجاهات الثمانية التي يمكن تحريك مقبض التحكم وفقها: أعلى، أسفل، يمين، يسار، إضافة إلى الاتجاهات القطرية الأربعة، وضغطة زر إضافي، إضافة إلى الجمع ما بين الحركات السابقة وضغطة الزر، أو عدم تفعيل أي عنصر تحكم، ولكن لا تعتمد جميع الألعاب على الاحتمالات السابقة جميعها، والتي يبلغ عددها 18، بل إن بعضها لا يستخدم سوى أربعة فقط.
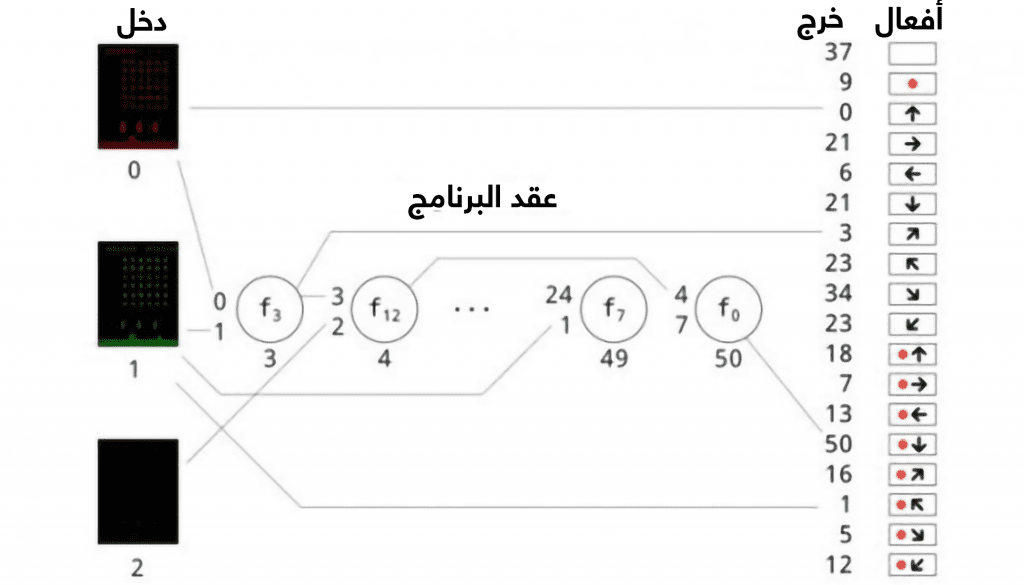
يجب أولاً تشكيل الكود، ويتطلب الأسلوب التطوري مجموعة من المفردات البرمجية التي يمكن تجميعها للحصول على كود برمجي. وتتراوح المفردات ما بين أفعال بسيطة مثل (x+y)/2 وأفعال أكثر تعقيداً مثل "أعط على الخرج العنصر إكس ذي القيمة الوحيدة إذا كان إكس سلمياً".
إن اختيار المفردات التي تشكل هذه المجموعة هام للغاية، ويستخدم ويلسون وزملاؤه مجموعة محددة مسبقاً للبرمجة الجينية الديكارتية (كما يسمون تقنيتهم). تبدأ العملية بتشكيل كود مؤلف من 40 مفردة عشوائية، ويمثل هذا الكود "جينوم" البرنامج. ومن ثم يختبر الجينوم لرؤية مهارته في اللعب، وذلك بأخذ نتيجة اللعبة كمعيار. واعتماداً على الأداء، يعاد إنتاجه واختبار أداءه مرة أخرى، وهكذا دواليك. وقد اختبر الفريق 10,000 جينوم بهذه الطريقة.
تعتبر النتائج مثيرة للاهتمام. ففي البداية، كانت الجينومات سيئة للغاية في اللعب، ولكن بمرور الوقت، تحسنت مهارتها. وبعد الكثير من الأجيال، أصبحت تلعب بمهارة تفوق مهارة البشر.
انتهى المطاف بالكثير من الجينومات باعتماد أساليب جديدة تماماً في اللعب، وغالباً ما كنت هذه الأساليب معقدة، ولكنها في بعض الأحيان وجدت أساليب بسيطة ولكن غفل عنها البشر. وعلى سبيل المثال، عند ممارسة لعبة كونج فو ماستر، اكتشفت الخوارزميات التطورية أن أفضل هجوم كان اللكمة بوضعية القرفصاء، حيث أن القرفصاء تتيح تجنب كل الرصاص ومهاجمة أي شيء قريب. واعتمدت الخوارزمية استراتيجية قائمة على تكرار هذه المناورة بدون أية أفعال أخرى. وبعد دراسة الموضوع، يبدو من المعقول الاقتصار على هذه الحركة.
تفاجأ اللاعبون البشر المشاركون في الدراسة بهذه الطريقة. يقول ويلسون وشركاؤه: "إن استخدام هذه الطريقة بشكل متعمد حقق نتائج أفضل مما في حالة اللعب الطبيعي، ويستخدم المؤلف الآن اللكمات في وضعية القرفصاء حصرياً في هذه اللعبة".
بشكل عام، لعب الكود المتطور بشكل جيد في الكثير من الألعاب أيضاً، بل تفوق حتى على البشر في ألعاب مثل كونج فو ماستر. ومن النتائج المهمة أيضاً أن الكود المتطور يضاهي أساليب التعلم العميق ويتفوق عليها أحياناً في ألعاب مثل أستيرويدز وديفيندر وكونج فو ماستر. إضافة إلى هذا، فقد أعطت الطريقة هذه النتائج بسرعة أكبر. يقول ويلسون وشركاؤه: "على الرغم من أن البرامج صغيرة نسبياً، فإن الكثير منها قادرة على المنافسة بقوة مع أحدث الأساليب لاختبار أتاري، وتتطلب وقتاً أقل للتدريب".
أما الكود المتطور نفسه فهو فائدة أخرى. ونظراً لصغر حجمه، من السهل رؤية كيفية عمله. من ناحية أخرى، فإن تقنيات التعلم العميق تعاني من مشكلة معروفة، وهي استحالة معرفة سبب اتخاذها لقرارات معينة، ويمكن أن يؤدي هذا إلى مشاكل عملية وقانونية.
بشكل عام، يعتبر هذا العمل مثيراً للاهتمام، ويقترح أن علماء الحاسوب الذي يركزون حصراً على التعلم العميق يفوتون على أنفسهم فرصاً كثيرة. وتعتبر المقاربة التطورية بديلاً قوياً يمكن تطبيقه في العديد من الحالات، وبالفعل، فقد بدأ بعض الباحثين باستخدامها لتطوير آلات تعلم عميق أكثر قوة. ما الذي يمكن أن يحدث؟
مرجع: https://arxiv.org/abs/1806.05695: تطوير برامج بسيطة لممارسة ألعاب أتاري