
عادة ما يحتاج التعلم الآلي إلى الكثير من الأمثلة. فحتى يتمكن نموذج الذكاء الاصطناعي من التعرف على حصان، يجب أن تريه الآلاف من صور الأحصنة. وهو ما يجعل هذه التكنولوجيا مكلفة من الناحية الحاسوبية، ومختلفة للغاية عن التعلم البشري؛ فغالباً ما يحتاج الطفل إلى رؤية بضعة أمثلة وحسب للجسم المعني، بل حتى مثال واحد فقط، قبل أن يصبح قادراً على التعرف عليه مدى الحياة.
وفي الواقع، فإن الأطفال لا يحتاجون في بعض الأحيان إلى أي مثال للتعرف على الأشياء. وعلى سبيل المثال، إذا عُرضت صور للحصان وأخرى لوحيد القرن على الأطفال، وقيل لهم إن الحصان وحيد القرن يمثل هجيناً بين الاثنين، فسوف يتمكنون من التعرف على صورة لهذا المخلوق الخرافي في كتاب صور ما أن يروها.

والآن، يشير بحث جديد من جامعة واترلو في أونتاريو إلى أن نماذج الذكاء الاصطناعي يجب أن تكون قادرة على فعل نفس الشيء أيضاً، وهي عملية يطلق عليها الباحثون اسم التعلم “بأقل من فرصة واحدة”، أو اختصاراً التعلم بطريقة لو-شوت. هذا يعني أن النموذج سيكون قادراً على التعرف (وبدقة) على أجسام تفوق في عددها عدد الأمثلة التي تم تدريبه عليها. قد يمثل هذا التطور فرقاً كبيراً في مجال تزايدت تكاليفه وصعوبة العمل فيه بشكل مطرد مع تضخم مجموعات البيانات المستخدمة للتدريب.
كيف يعمل التعلم بطريقة لو-شوت
استعرض الباحثون الفكرة أولاً بإجراء تجربة على مجموعة البيانات الشهيرة المستخدمة للرؤية الحاسوبية، والمعروفة باسم منيست (MNIST). تحتوي هذه المجموعة على 60,000 صورة تدريبية لأرقام من الواحد حتى التسعة كُتبت بشكل يدوي، وغالباً ما تُستخدم لتجربة الأفكار الجديدة في حقل الذكاء الاصطناعي.
في ورقة بحثية سابقة، اقترح باحثون من جامعة إم آي تي طريقة من أجل “تقطير” مجموعات البيانات العملاقة إلى مجموعات صغيرة، ومن أجل تجربة هذه الفكرة، قاموا بضغط مجموعة منيست إلى 10 صور فقط. لم تكن الصور مُختارة من المجموعة الأصلية، بل مصممة بعناية ومُحسّنة إلى أقصى درجة ممكنة كي تكون مكافئة للمجموعة الكاملة من ناحية المعلومات التي تحويها. ولهذا، عندما يتم تدريب نموذج الذكاء الاصطناعي على هذه الصور العشر فقط، يمكن له أن يحقق دقة قريبة للغاية من دقة النموذج المُدرب باستخدام كامل مجموعة منيست الأصلية.
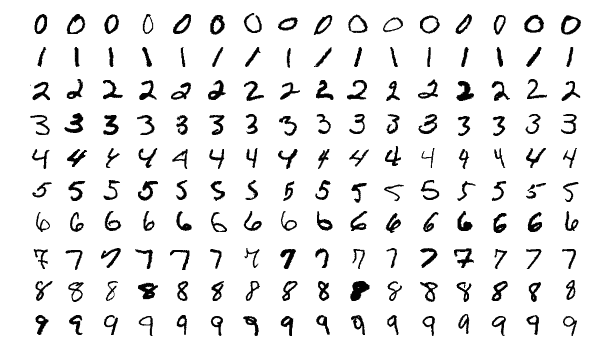

قرر باحثو واترلو تطوير عملية التقطير هذه. فإذا كان من الممكن تقليص 60,000 صورة إلى 10، فما الذي يمنع تقليصها إلى خمس صور؟ أدرك الباحثون أن الحيلة تكمن في تشكيل صور تضم عدة أرقام في نفس الوقت، ومن ثم تلقيمها إلى نموذج ذكاء اصطناعي باستخدام تصنيفات هجينة أو “رخوة” (يمكن أن نفكر هنا في حصان ووحيد قرن يمتلكان ملامح جزئية من الحصان وحيد القرن).
يقول إيليا سوتشولوتسكي، وهو طالب دكتوراه في واترلو، والمؤلف الرئيسي للبحث: “إذا نظرنا إلى الرقم 3، فسوف نلاحظ أنه يشبه الرقم 8، ولكنه لا يشبه الرقم 7 على الإطلاق. تحاول التصنيفات الرخوة التقاط هذه الملامح المشتركة. وبالتالي، بدلاً من أن نقول للآلة: (هذه الصورة تمثل الرقم 3)، نقول: (هذه الصورة تتألف من الرقم 3 بنسبة 60%، والرقم 8 بنسبة 30%، والرقم 0 بنسبة 10%)”.
حدود التعلم بطريقة لو-شوت
ما أن نجح الباحثون في استخدام التصنيفات الرخوة لتحقيق التعلم بطريقة لو-شوت على منيست، بدؤوا يفكرون في حدود تطبيق هذه الفكرة فعلياً. هل عدد الفئات -التي يمكن تعليم أحد نماذج الذكاء الاصطناعي التعرفَ عليها باستخدام عدد صغير من الأمثلة- محدود؟
من المفاجئ أن الجواب هو النفي، على ما يبدو. فباستخدام تصنيفات رخوة ودقيقة التصميم، يمكن ترميز أي عدد من الفئات باستخدام مثالين وحسب من الناحية النظرية. يقول سوتشولوتسكي: “يمكن باستخدام نقطتين وحسب فصلَ ألف صنف أو عشرة آلاف صنف أو حتى مليون صنف”.
وهو ما بينه الباحثون في بحثهم الجديد، وذلك باستخدام طريقة رياضية بحتة؛ فقد تلاعب الباحثون بواحدة من أبسط خوارزميات التعلم الآلي، التي تعرف باسم الجيران الأقرب من المرتبة “كي” (اختصاراً: كي إن إن)، التي تصنف الأجسام باستخدام مقاربة بيانية (رسومية).
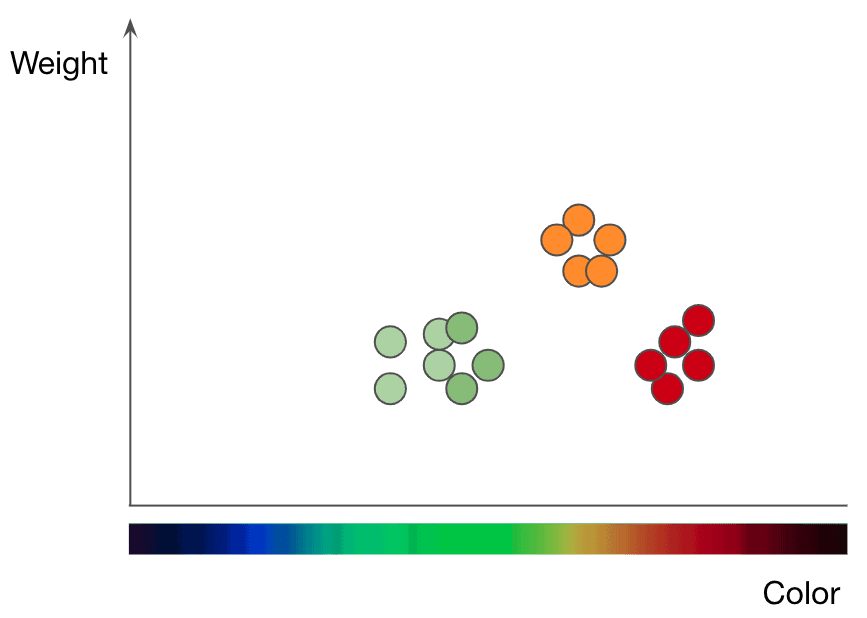
ولفهم عمل كي إن إن، يمكن أن نأخذ تصنيف الفواكه كمثال؛ فإذا رغبنا في تدريب نموذج كي إن إن على استيعاب الفرق ما بين التفاح والبرتقال، يجب أولاً أن نختار الميزات التي نريد استخدامها لتمثيل كل نوع من الفاكهة. سنفترض أننا اخترنا اللون والوزن، ولهذا، بالنسبة لكل تفاحة وبرتقالة، يجب أن نلقم نظام كي إن إن نقطة بيانات واحدة تمثل اللون وتلعب دور الإحداثي إكس، والوزن للإحداثي واي. بعد ذلك، تقوم خوارزمية كي إن إن برسم جميع نقاط البيانات على شكل بياني ثنائي الأبعاد، وترسم حداً يفصل ما بين التفاح والبرتقال. وحتى الآن، يبدو الشكل البياني مقسوماً بشكل واضح إلى صنفين، وتستطيع الخوارزمية الآن أن تقرر ما إذا كانت نقاط البيانات الجديدة تمثل صنفاً أو آخر وفق موقعها بالنسبة للحد الفاصل.
ولدراسة التعلم بطريقة لو-شوت مع خوارزمية كي إن إن، قام الباحثون ببناء سلسلة من مجموعات البيانات الصغيرة المصطنعة، وقاموا بتصميم تصنيفاتها الرخوة بعناية. وبعد ذلك، جعل الباحثون خوارزمية كي إن إن ترسم الحدود الفاصلة كما تراها، ووجدوا أنها نجحت في فصل الشكل البياني إلى عدد من التصنيفات يفوق عدد نقاط البيانات. أيضاً، قام الباحثون بعملية تحكم دقيقة بمواضع الحدود الفاصلة. وباستخدام تعديلات متنوعة على التصنيفات الرخوة، تمكنوا من جعل خوارزمية كي إن إن ترسم أنماطاً محددة تشبه الأزهار.
توجد حدود لهذه التجارب النظرية، بطبيعة الحال. وبالرغم من أن فكرة التعلم بطريقة لو-شوت يجب أن تكون قابلة للتطبيق على خوارزميات أكثر تعقيداً، إلا أن مهمة تصميم الأمثلة رخوة التصنيف تصبح أكثر صعوبة بكثير. إن خوارزمية كي إن إن قابلة للتمثيل البصري، ويمكن استيعابها بسهولة، ما يجعل تصميم التصنيفات ممكناً بالنسبة للبشر، أما الشبكات العصبونية فهي أكثر تعقيداً وغموضاً، ما يعني أن هذا لا ينطبق عليها على الأرجح. إضافة إلى ذلك، فإن تقطير البيانات الذي يمكن استخدامه لتصميم الأمثلة رخوة التصنيف للشبكات العصبونية لا يخلو من السلبيات؛ حيث يتطلب البدء بمجموعة بيانات ضخمة حتى يتم تقليصها إلى شيء أكثر فعالية.
يقول سوتشولوتسكي إنه يعمل الآن على البحث عن أساليب أخرى لتصميم هذه المجموعات المصطنعة الصغيرة من البيانات، سواء بتصميمها يدوياً أو بخوارزمية أخرى. وعلى الرغم من هذه التحديات البحثية الإضافية، فإن البحث يثبت صحة الأسس النظرية للتعلم بطريقة لو-شوت. ويقول: “نستنتج أنه يمكن أن نحقق كسباً هائلاً في الفعالية اعتماداً على طبيعة مجموعة البيانات”.
هذا أكثر ما يثير تونجزو وانج، وهو طالب دكتوراه في إم آي تي وكان قائد البحث السابق حول تقطير البيانات. ويقول متحدثاً عن مساهمة سوتشولوتسكي: “يسعى هذا البحث إلى تحقيق هدف جديد وهام للغاية: تعليم نماذج قوية باستخدام مجموعات بيانات صغيرة”.
ويعبر ريان كورانا، وهو باحث في معهد مونتريال لأخلاقيات الذكاء الاصطناعي، عن نفس الفكرة: “أهم ما في الأمر هو أن التعلم بطريقة لو-شوت سيخفض إلى درجة كبيرة من متطلبات البيانات اللازمة لبناء نموذج ناجح”. وهو ما يعني أن الذكاء الاصطناعي سيصبح متاحاً أمام العديد من الشركات والصناعات التي لم تكن قادرة من قبل على توفير متطلبات البيانات لهذا الحقل. كما يمكن أن تساهم هذه الطريقة في تحسين خصوصية البيانات، وذلك لقلة كمية المعلومات التي يجب استخلاصها من الأفراد لتدريب نماذج مفيدة.
يؤكد سوتشولوتسكي على أن البحث ما زال في بداياته، ولكنه يشعر بالحماس بلا شك. ويقول إن ردة الفعل الأولية لزملائه في كل مرة عرض بحثه عليهم كانت القول بأن الفكرة مستحيلة. ولكن، عندما يدركون فجأة أنها ليست كذلك، يكتشفون أنها تفتح المجال أمام عالم كامل من الإمكانات.