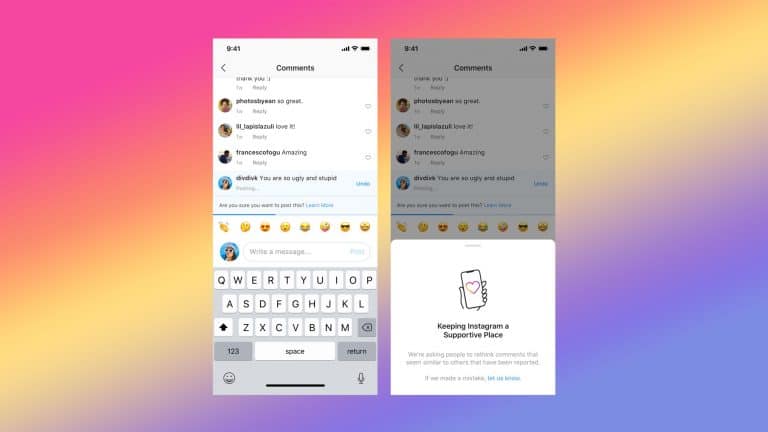
ستقوم منصة التواصل الاجتماعي بتحديد التعليقات التي يُحتمل أنها مسيئة قبل نشرها، وتطلب من المعلق إعادة النظر فيها.
خلفية الخبر
لطالما كانت الإساءات على الإنترنت مسألة معقدة بسبب حجمها وتفاصيلها، وهناك جدل متواصل حول ما يجب اعتباره يستحق الحذف، فإذا زادت الفلترة ستؤثر على إمكانية التعبير عن النفس، وإذا قلت ستؤدي إلى ظهور بيئة سلبية، ناهيك عن تعقيدات اختلافات اللغات والثقافات والمعايير، مما يجعل من هذا التحدي صعباً للغاية.
الذكاء الاصطناعي
لهذا السبب، لجأت منصات التواصل الاجتماعي مثل فيسبوك إلى الذكاء الاصطناعي لمساعدتها على التعامل مع الحجم الهائل من المنشورات والتعليقات. ولكن لطالما كان فهم اللغة أمراً صعباً على الذكاء الاصطناعي، ويمكن لأشياء بسيطة -مثل المعاني المزدوجة أو التهكم أو حتى أخطاء التهجئة- أن تُربك النظام ويخطئ فهمها. وللالتفاف حول هذه المشكلة، تُوظف فيسبوك الآلاف من مراقبي المحتوى الذين يمكنهم أن يتدخلوا عندما تعجز الخوارزميات عن اتخاذ القرار. غير أن التحقيقات كشفت أن هؤلاء الموظفين يعملون في ظروف صعبة للغاية.
حل إنستقرام
تجرب منصة إنستقرام التي تمتلكها فيسبوك حلاً جديداً، فبدلاً من الاتكال فقط على خوارزمياتها لحذف المواد المسيئة، ستعتمد أيضاً على المستخدمين للقيام بالحذف بأنفسهم. فعند نشر تعليق، إذا قام نموذج الذكاء الاصطناعي بوضع علامة عليه بوصفه مؤذياً، فسيرى الناشر رسالة تقول: "هل أنت متأكد من أنك تريد نشر هذا التعليق؟".
في الاختبارات الأولى، وجدت المنصة أن هذه الميزة شجعت الكثيرين على التراجع عن تعليقاتهم، وذلك وفقاً لإعلان نُشر مؤخراً. إنه أسلوب ذكي لمحاولة تخفيف شيء من العبء عن مراقبي المحتوى البشريين من دون فرض قيود شديدة.
بيانات التدريب
ليست هذه المرة الأولى التي تستخدم فيها إنستقرام الذكاء الاصطناعي لمراقبة المحتوى اللغوي. ففي يناير من عام 2017، أطلقت فلتر تعليقات مسيئة يعتمد على التعلم الآلي لإخفاء معظم التعليقات المسيئة الواضحة. ومن ذلك الحين، استمرت المنصة في تحسين نموذج التعلم الآلي، معتمدة في الغالب على ملايين نقاط البيانات التي ولَّدها المستخدمون عند الإبلاغ عن التعليقات من قبل. وتتضمن الميزة الأحدث أيضاً الطلب من المستخدمين أن يقوموا بإعلام المنصة إذا قامت باعتبار المحتوى مسيئاً عن طريق الخطأ، وهي حلقة تغذية راجعة أخرى يمكن أن تقدم المزيد من بيانات التدريب المفيدة.